오디오 데이터 전처리 (2)에서 이어지는 글입니다. 2편에서는 waveform에 푸리에 변환을 통해 spectrum을 뽑고, 각 frame을 옆으로 쌓아 시간 정보를 살려주는 spectrogram에 대해 알아봤습니다. 3편에서는 지난 푸리에 변환 단계에 이어서 audio feature extraction 과정을 설명하기 전에 잠깐 전처리 흐름에서 벗어나 cepstrum analysis에 대해 알아보겠습니다.
Index
오디오 데이터 전처리 (2) Fourier Transform & Spectrogram
오디오 데이터 전처리 (4) Mel Filter Bank

다시 전체적인 흐름에서 보면 우리는 FFT를 통한 spectrum까지 왔다. 그다음 단계로 진행하기 전에 Cepstrum analysis 라는 분석 과정에 대해 알아보자.
Cepstrum
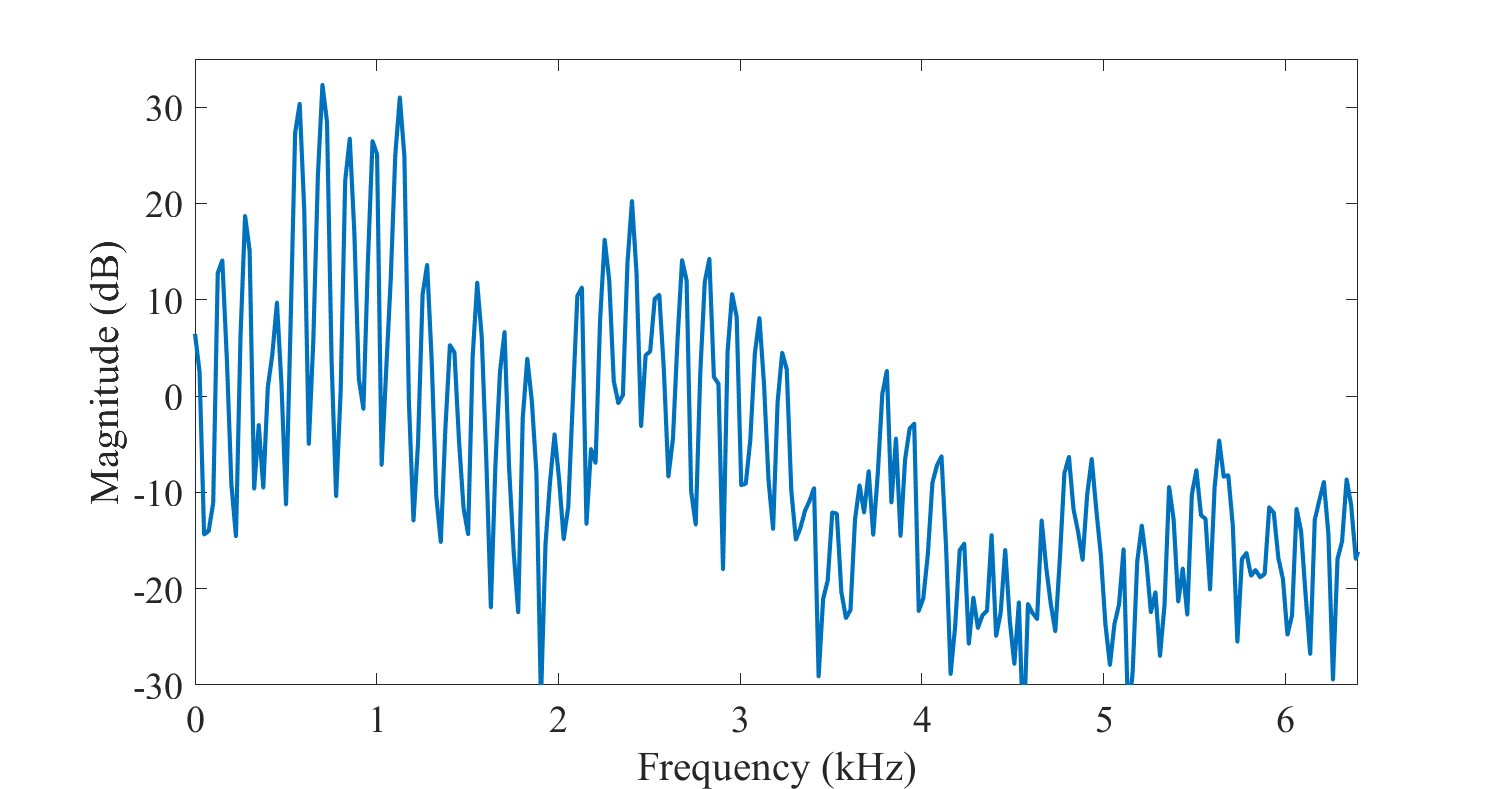
power spectrum은 모음과 같이 speech signal에 있어서 중요한 정보를 모두 담고 있지만, 다음 그래프에서 처럼 보이듯 그 값의 범위가 일정하지 않다.

반면 Log-spectrum은 값의 크기가 스펙트럼 전체에서 균일하게 시각화해주고 이를 통해 추가적인 분석을 할 수 있다.
사람의 목소리는 기본 주파수(F0 : fundamental frequency)와 배음(harmonics)으로 이루어진다. 기본 주파수는 정현파(사인파) 요소 중 가장 작은 주파수이고, 배음은 기본 주파수의 정수배로 발생한다. 소리가 공명되는 특정 주파수를 음형(formant)라고 하는데, 제1(F1), 제2 음형대(F2)의 주파수에 따라 모음이 달라지고 이러한 현상을 조음(articulation)이라고 한다.
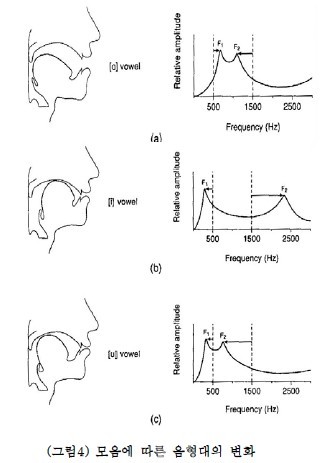
하지만 공명 주파수가 배음 주파수와 어긋나면 formant를 찾기가 어렵다. 따라서 Cepstrum을 통해 F0을 구하고 이를 통해 F0의 정수배인 harmonic peak를 분리할 수 있다. Log-spectrum에 역푸리에 변환(IFFT)을 취하면 다음과 같이 Cepstrum을 구할 수 있다.

Cepstrum에서 삐죽 튀어 나온 부분(7ms)이 기본 주파수(fundamental frequency)를 나타낸다. 기본 주파수를 계산해보면 다음과 같다.
$F = \frac{1}{T}$
$T = 7ms = 0.007s$
$F = \frac{1}{0.007} = 143Hz = 0.143kHz$
즉 log spectrum에 harmonic peak가 기본 주파수 0.143kHz의 정수배마다 일어남을 알 수 있다. 이는 log spectrum 그래프에서, frequency가 1이 될 때까지 harmonic peak가 7번 있음을 의미한다. 정리하자면 Cepstrum은 spectrum의 harmonic peak 간 간격을 구하기 위한 방법이고, harmonic peak 간 간격이 기본 주파수(F0 ; Fundametal frequency)가 된다.
Spectrum은 각 주파수 대역의 진폭과 위상을 설명하지만 Cepstrum은 주파수 대역 간의 변동을 특성화해준다. 즉 cepstrum이 spectrum보다 좀 더 깊은 core한 정보를 가지고 있다고 할 수 있다. 따라서 우리는 spectrum 단이 아닌 cepstrum 단에서 feature extraction을 하고자 한다. 앞서 cepstrum을 구하는 방법을 언급했으나 보다 정확한 논의를 위해 cepstrum에 대해 다음과 같이 다시 정의한다.
Cepstrum의 기본 아이디어는 푸리에 변환에 의해 신호를 주파수 영역으로 변환한 다음, 다시 이 spectrum을 하나의 신호 인 것처럼 다른 변환을 수행하는 것이다. 이렇게 cepstrum을 구하는 방법은 3가지가 있다.
(1) Fourier transform -> Complex log -> Fourier transform
(2) Fourier transform -> Complex log -> Inverse Fourier transform
(3) Fourier transform -> 제곱 (power spectrum) -> Mel-filter bank -> Real log -> Discrete cosine transform(DCT)
음성인식에서는 이 중 (3) 방법을 사용한다.
(1), (2), (3) 알고리즘 결과가 어떻게 같을까.. 결과 값이 같은게 아니라 cepstrum이라는 개념 하에서 동일한 의미를 지닌다는 걸까. 아무리 생각해도 그냥 푸리에 변환하고 역푸리에 변환이 같은 역할을 하는 위치에 있는 게 이상한데 말이다..
혼자 고민하다 TensorFlow Korea 그룹에 질문을 올렸는데, 김종욱 님께서 멋진 답변을 해주셔서 위 의문이 어느정도 해결되었다!! 해당 내용 전문을 인용하고 내 나름대로 정리를 해보겠다.
"주파수 스펙트럼에서 양수 부분만 표시하긴 하지만 사실 음수 부분에도 complex conjugate들로 이루어진 대칭 모양의 스펙트럼이 있는 셈이라, “세로축 기준으로 대칭시켜서 우함수(even function)로 만들어서 푸리에변환하는”=DCT하는 것이 적절해 보입니다. 상수배/켤레복소수 차이나는 것을 제외하면 푸리에 변환과 역변환의 차이가 없어서 특징 추출 기법으로서 역변환인지 아닌지를 구분하는게 큰 의미가 없기도 해요"
첫번째 문단은, 푸리에 변환과 DCT가 하는 역할이 같다는 걸 말씀해주신 것 같고, 두번째 분단은 푸리에 변환과 역 변환간에 상수배/켤레복소수 차이를 제외하면 차이가 없어서 두 변환을 구분하는게 큰 의미가 없다고 해주셨다. 즉, cepstrum을 구하는 위에 3가지 방법들이 서로 다른 변환을 취하지만 결국에는 동일한 역할을 한다고 볼 수 있겠다.
Reference
Oppenheim, A. Schafer, R. (1968). Speech Dynamics Analysis of Audio and Electronic Acoustics (IEEE)
Introduction to speech processing(7E) https://wiki.aalto.fi/display/ITSP/Cepstrum+and+MFCC
모두의 연구소 음성인식 부트캠프
변요한의 블로그 https://blog.byunyohan.com/41
'Audio & Speech' 카테고리의 다른 글
| 오디오 데이터 전처리 (2) Fourier Transform & Spectrogram (2) | 2020.03.25 |
|---|---|
| 오디오 데이터 전처리 (4) Mel Filter Bank (2) | 2020.03.25 |
| [Sound AI #12] 음악 장르 classification - 1. 데이터 전처리(Python) (0) | 2020.03.08 |
| [Sound AI #11] 오디오 데이터 전처리 (Python Coding) (12) | 2020.03.06 |
| [Sound AI #10] 오디오 데이터 전처리 (이론) (1) | 2020.03.06 |



