Sound of ai 12강, Music Genre classification을 위한 데이터 셋을 준비하는 강의를 공부하며 정리한 글 입니다.
지난 포스팅(#11)에서 살펴본 MFCC feature를 이용해 음악 장르 분류하는 모델을 만들어 보려 한다. 데이터 셋은 http://marsyas.info/downloads/datasets.html 에 Music Genre Classification 데이터 셋을 사용했다. 이는 블루스, 재즈, 클래식, 팝 등 총 10개의 장르별 음원이 100개씩 있는 데이터다. MFCC와 라벨링 작업을 한번에 하는 함수를 구현해보겠다.
DATASET_PATH = "/content/drive/My Drive/data/genres_Classification_data"
JSON_PATH = "data_10.json"
SAMPLE_RATE = 22050
TRACK_DURATION = 30 # sec
SAMPLES_PER_TRACK = SAMPLE_RATE * TRACK_DURATION # 한 track의 sample 수
def save_mfcc(dataset_path,json_path, n_mfcc, n_fft, hop_length, n_segments ):
# wav 파일에서 MFCC를 추출하고, 장르 라벨과 함께 json 파일로 저장하기 위한 함수
# dataset_path (str): Path to dataset
# json_path (str): Path to json file used to save MFCCs
# n_mfcc (int): Number of coefficients to extract
# n_fft (int): 한 frame 당 sample 수
# hop_length (int): 겹치는 frame의 sample 수
# n_segments (int): 트랙자체를 split 시켜 데이터 Augmentation 효과를 주자
# mapping, labels, and MFCCs 를 저장할 data라는 딕셔너리 생성
data = { "mapping": [],"labels": [],"mfcc": [] }
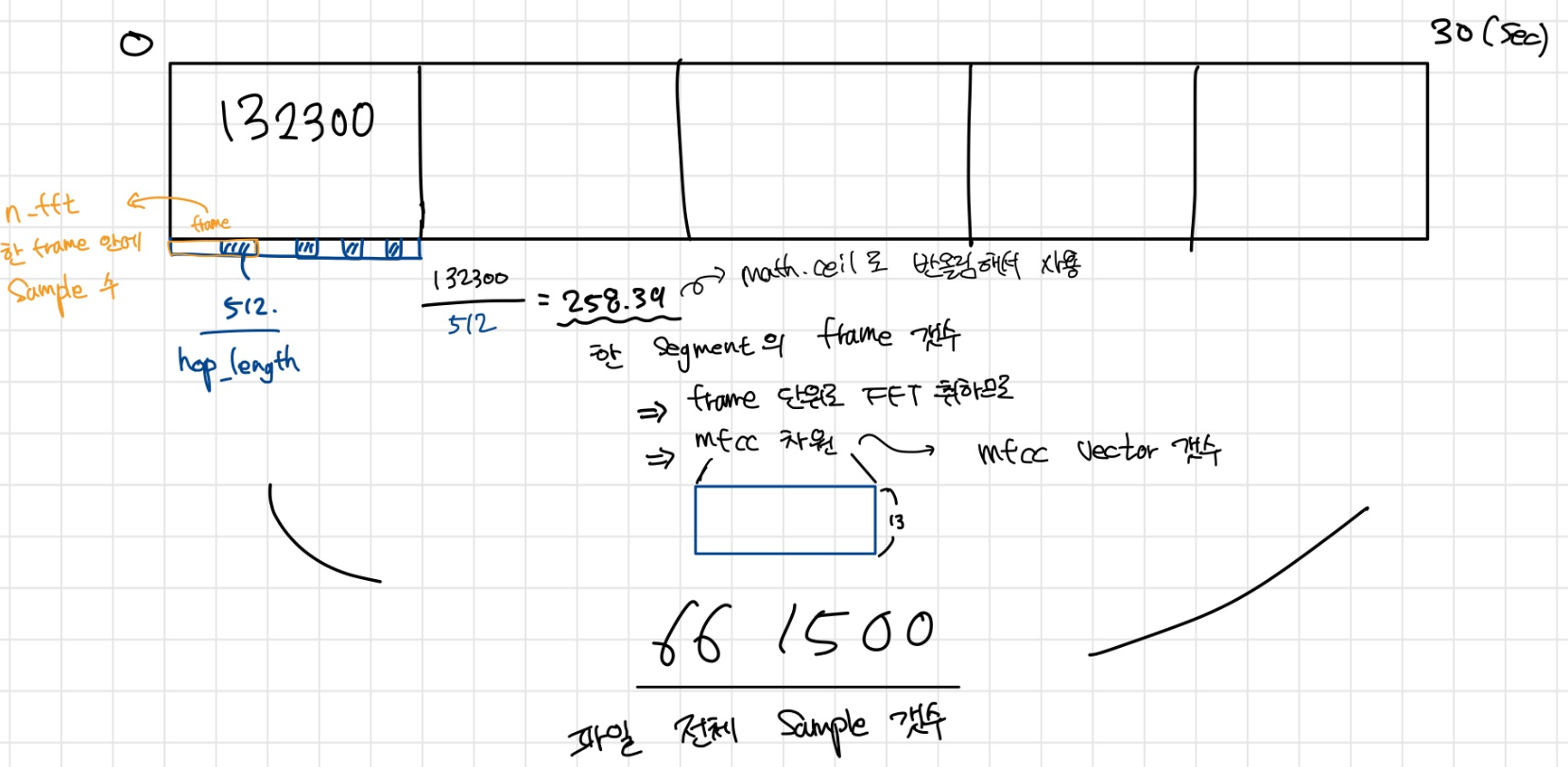
samples_per_segment = int(SAMPLES_PER_TRACK / n_segments) # track 전체 sample을 segment 수로 나눠서, segment 당 sample 수 정의
num_mfcc_vectors_per_segment = math.ceil(samples_per_segment / hop_length) # 굿노트 필기
# 모든 sub 폴더에 대해 loop
for i, (dirpath, dirnames, filenames) in enumerate(os.walk(dataset_path)): # eumerate 안에 argument를 풀어 매 iter 마다 인덱스와 결과값을 출력
# dirpath : 현재 경로, dirnames : 현재 경로상에 디렉토리 목록, filenames : 현재 경로상에 파일 목록
if dirpath is not dataset_path:
genre_label = dirpath.split("/")[-1]
data["mapping"].append(genre_label)
print("\n Processing : {}".format(genre_label))
# 각 장르 폴더 밑에, 음원 파일 precessing
for f in filenames:
file_path = os.path.join(dirpath,f) # 현재 dirpath와 file 이름을 경로명으로 이어준다
sig, sr = librosa.load(file_path, sr=SAMPLE_RATE)
# Augmentation을 위해 segment 하므로, 각 segment에 대한 processing
for d in range(n_segments):
# 각 segment의 시작, 끝 점을 지정
start = samples_per_segment * d
finish = start + samples_per_segment
# extract mfcc
mfcc = librosa.feature.mfcc(sig[start:finish], sr, n_mfcc=n_mfcc, n_fft=n_fft, hop_length=hop_length)
mfcc = mfcc.T
# input data 차원을 맞춰줘야 되기 때문에, 위에서 지정한 mfcc 차원에 맞으면 저장한다
if len(mfcc) == num_mfcc_vectors_per_segment:
data["mfcc"].append(mfcc.tolist()) # mfcc는 넘파이 어레이 이므로, list로 바꿔서 append 해준다
data["labels"].append(i-1)
print("{}, segment:{}".format(file_path, d+1)) # 음원 파일 경로, 각 음원의 d 번째 segment
with open(json_path, "w") as fp:
json.dump(data, fp, indent =4)
if __name__ == "__main__":
save_mfcc(DATASET_PATH,JSON_PATH,13,2048,512,5)
중요한 부분은 각주로 설명을 적어 놓았으나, MFCC 의 차원을 결정하는 다음의 코드에 대해 명확히 하려 한다.
samples_per_segment = int(SAMPLES_PER_TRACK / num_segments) # track 전체 sample을 segment 수로 나눠서, segment 당 sample 수 정의
num_mfcc_vectors_per_segment = math.ceil(samples_per_segment / hop_length)
우선, num_mfcc_vetors_per_segment는 한 segment 당 MFCC 벡터의 갯수 즉, 가로축 차원이 된다. 이는 한 segment에 있는 frame 수와 같은데, 이를 segment 당 sample 수(sample_per_segment)를 frame이 겹치는 부분의 sample 수(hop_length)로 나누어 구한다. 다음의 그림으로 이해해보자!
'Audio & Speech' 카테고리의 다른 글
| 오디오 데이터 전처리 (4) Mel Filter Bank (2) | 2020.03.25 |
|---|---|
| 오디오 데이터 전처리 (3) Cepstrum Analysis (3) | 2020.03.25 |
| [Sound AI #11] 오디오 데이터 전처리 (Python Coding) (12) | 2020.03.06 |
| [Sound AI #10] 오디오 데이터 전처리 (이론) (1) | 2020.03.06 |
| [음성인식] Lec.7 WFST(Weighted Finite-State Transducers) (0) | 2020.03.01 |



