이 시리즈는 스탠퍼드에서 제공하는 머신러닝 강의를 듣고 스터디를 진행하며 몰랐던 혹은 헷갈렸던 개념들 위주로 정리합니다
1. Feature Scaling

-
Scaling은 머신러닝에서 중요한 문제인데, 그 이유는 위 그림에서 알 수 있듯이 Gradient descent로 학습을 하는 속도에 영향을 주기 때문이다.
-
좌측 그림을 보면 x1 = size 변수와 x2 = number of bedrooms 의 data scale(범위, 크기)이 크게 차이난다. 이럴 경우 cost function이 그래프처럼 한 축으로 치우친 타원 꼴이 나오게 되고 gradient descent로 학습하는 과정에서 단번에 최적점으로 이동하지 못하고 왔다 갔다 하면서 시간이 많이 걸리게 된다.
-
따라서, Scaling을 통해 주어진 데이터의 범위를 균등하게 조정해주어, 오른쪽과 같이 cost function 그래프가 나오게 하고 학습의 효율을 높일 수 있다. Scaling 방법은 다음과 같다.
1) MinMax normalization
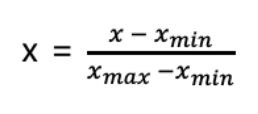
-
데이터의 범위를 0 ~ 1사이로 맞춰주는 scale 방법 데이터의 최대/최소만 알고 있어도 사용이 가능하다
2) Standardization

-
분모는 데이터의 표준편차, 이를 모를 경우 data range(Xmax - Xmin)으로 대체해도 괜찮다
-
range로 나눌 경우 데이터의 최소값을 -1 최대값을 1로 mapping하여 데이터 범위를 -1 ~ 1 로 맞춘다
-
표준편차로 나눌 경우 원래 데이터의 분산 정도는 보존하면서 범위를 균일하게 해준다 > Z분포
-
통계학에서는 표준화라고 부르는데 컴퓨터 과학이나 머신러닝 분야에서는 정규화라는 표현으로도 쓰이는 듯 하다.
※ Application tip ※
-
실제 적용에서는 데이터의 범위가 -3 ~ 3 보다 크거나 -0.3 ~ 0.3 보다 작은 경우 scaling을 해주는게 좋다고 한다.
-
물론 정형화된 방법은 없으며 여러 데이터를 다루면서 개인의 전처리 방법을 형성해 나가는게 중요 할 듯 하다.
-
anomaly detection과 같은 task의 경우 이상치 탐색을 위해 scaling시 zero - centering 시키지 않는 방법도 사용한다
2. Learning rate

- 기본적으로 learning rate가 너무 크면 gradient descent 과정에서 수렴하지 못하고 튕기는 문제가 발생하므로 적절히 작은 값으로 주는것이 중요하다.
- 좌상단 그림에서 처럼 cost function이 감소하지 않고 증가하는 경우 learing rate를 줄일 필요가 있는것이다.
- 그 밑에 그림의 경우 cost function의 local minima가 많음을 알 수 있다
- 하지만 learning rate가 너무 작을 경우 매우 천천히 수렴하는 문제가 발생할 수 있다 따라서 learning rate를 적절히 조절해 가며 학습하는 것이 중요!
3. polynomial regression
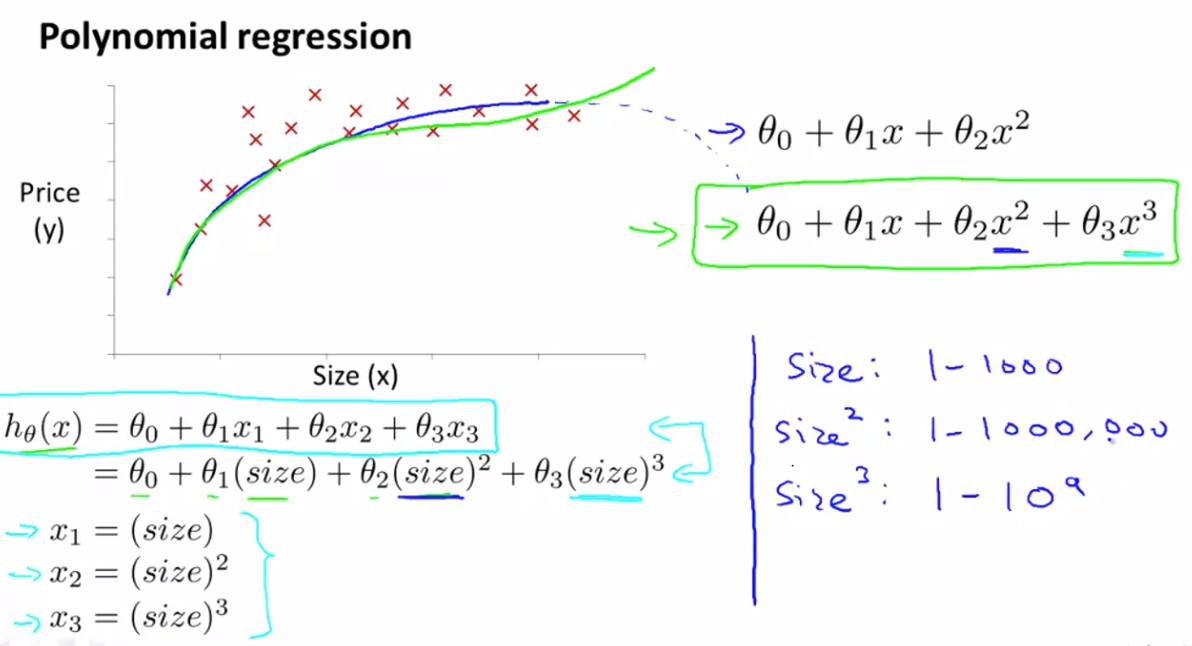
-
polynomial regression회귀에서는 각 변수의 데이터 범위가 그림과 같이 매우 크게 차이나므로 scaling할때도 신경을 써야 한다. 그림의 데이터의 경우 3차 모델인 cubic 모형을 사용하였는데, 변수마다 스케일이 크게 차이나므로 이를 고려해서 scaling 해야 한다.
'ML & DL' 카테고리의 다른 글
| [NLP] Seq-to-Seq (0) | 2019.12.07 |
|---|---|
| [딥러닝]RNN과 LSTM (0) | 2019.11.18 |
| [머신러닝]SVM(Support Vector Machine) by MIT (0) | 2019.11.16 |
| 텍스트 전처리(Boaz NLP 1팀) (0) | 2019.10.31 |
| [머신러닝]Machine learning (stanford) 1강 - Gradient descent (0) | 2019.10.26 |



