본 내용은 스탠포드 CS231n 강의와 ratsgo's blog, 보아즈 13기 정상형씨의 설명을 기반으로 작성되었습니다.
RNN이란?
RNN은 기존 NN과 다르게 시퀸스 모델이다. 다시 말해 밑에 그림에서 초록색으로 표현되는 히든 노드가 방향을 가지고 연결되어 있는 NN이다. 이렇게 네트워크 구조를 구성하면, 음성/텍스트 등 순차적인 데이터 처리에 강한 모습을 보인다. 기존의 NN과 다르게 예전 데이터의 정보가 어느정도 보존되면서 뒤쪽 layer로 흘러 들어가, 각 데이터간 상관 관계나 시계열성을 고려해야하는 데이터에 적합한 모델이 되는 것이다.

RNN에 인풋 데이터(그림에서 분홍색)와 아웃풋(파란색)은 다양한 길이의 데이터를 받고, 리턴 할 수 있어 task 목적에 따라 다양하고 유연한 구조를 만들 수 있다. 예를 들어 한글을 영어로 번역한다 했을 때, 한국어의 임배딩 벡터 갯수 만큼 영어 단어가 아웃풋으로 나오는게 아니다. 이렇듯 유연한 구조를 만들 수 있는데 RNN의 특징이다.
RNN으로 할 수 있는 여러 task가 있지만 그 중 가장 대표적인 것은 사진 데이터를 받아 그것에 대해 설명하는 Image captioning, 여러 단어 데이터를 받아 감정을 출력해주는 감정분석, 파파고와 같은 번역 등이 있다. 위 그림에서와 같이 각 task에 따라 RNN의 구조가 달라짐을 알 수 있다.
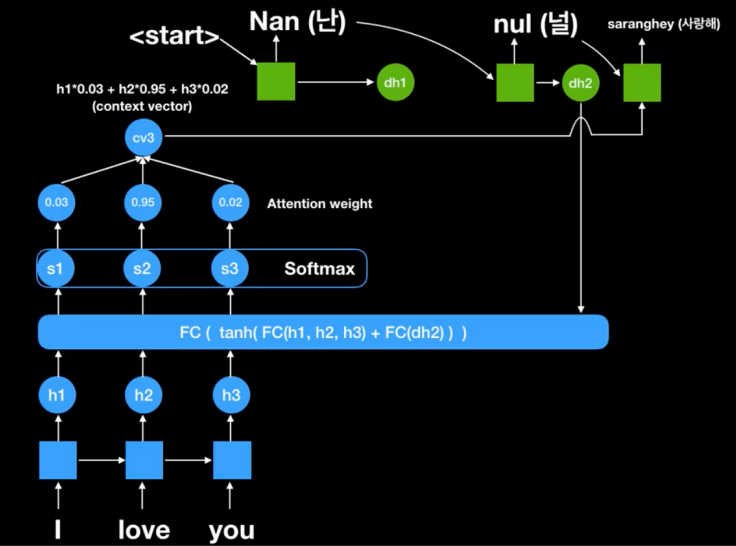
NLP에서 임배딩 벡터는 크고 다양한 데이터를 통해 뽑아내고(기본적으로 300차원 정도, 이 300차원 안에 벡터 값들은 위치,의미,상관,관계 등 여러 정보를 가지게 된다) 보통 한 단어가 하나의 인풋 벡터로 들어가게 된다. 예를 들어 I love you에 경우 I 벡터 love 벡터 you 벡터가 각각 300차원의 인풋 벡터로 들어가게 된다.
RNN 기본 구조
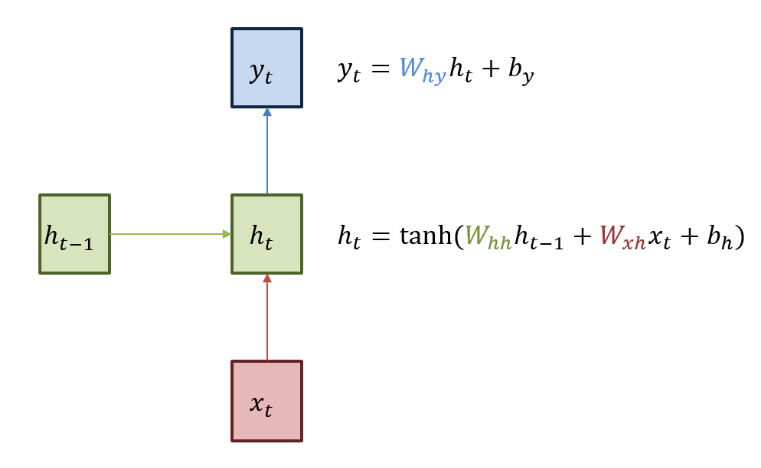
RNN의 기본 구조는 위 그림과 같다. 앞서 언급한 바와 같이 초록색 박스는 히든 state를 의미한다. 아웃풋은 인풋 데이터 x와 이때까지의 layer를 통과해온 히든 state를 더해 activation function을 거쳐 갱신되게 된다. 여기서는 비선형 함수인 tanh를 사용한다. RNN 모델의 Weight는 딱 3개만 있다. Input data에서 hidden state로 넘어갈 때 곱해지는 Wxh, 이전 hidden state에서 다음 hidden state로 넘어갈 때 곱해지는 Whh, hidden state에서 ㅐoutput으로 넘어갈때 곱해지는 Why.
이렇게 RNN에서 단 3개의 Weight로 전체 모델을 공유하는 이유는 인풋, 아웃풋 데이터 size를 가변적으로 이용하기 위해서이다.
첫 hidden state는 보통 0으로 initialize 해준다.
cf) 왜 딥러닝에서 activation function은 비선형함수를 사용할까?
f(x) = ax 와 같이 activation function을 선형 함수로 하게 되면, 이를 n번 layer 통과시켜도 y(x) = a^n*x이므로 결국 선형 함수로 표현이 된다. 즉 y(x) = cx 이런식으로 표현이 된다는 얘기다. 따라서 layer를 쌓는 효과를 얻기 위해선 activation function은 비선형 함수를 사용해야한다.
RNN backpropagation
RNN의 역전파(backpropagation) 과정은 기존의 NN와 동일하다.

many-to-many의 모델에서는 각각의 아웃풋에 대해 Loss를 계산한 뒤, backpropa를 진행한다. 각 Gradient들은 hidden state로 흘러 들어오면서 더해지며 Backpropa를 진행한다.
자 그럼 이때까지 공부한 RNN을 정리해보자.
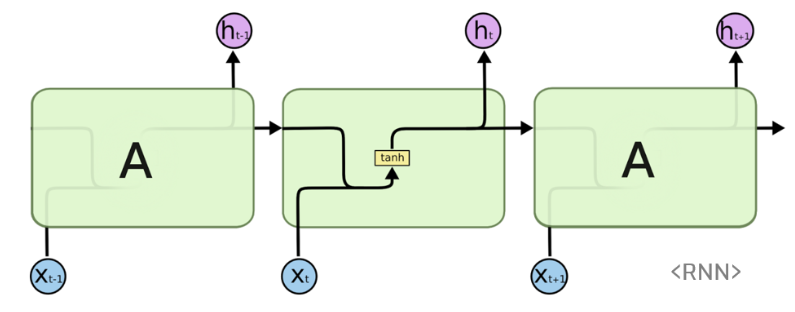
t 시점의 인풋 데이터 Xt는 들어가면서 이전의 히든 state 정보와 합쳐지고 tanh func.을 통과하게 된다. 통과한 값은 t 시점 히든 state가 되고 다음 layer로 들어가게 된다. 이 과정을 반복하는게 RNN의 데이터 흐름이다.
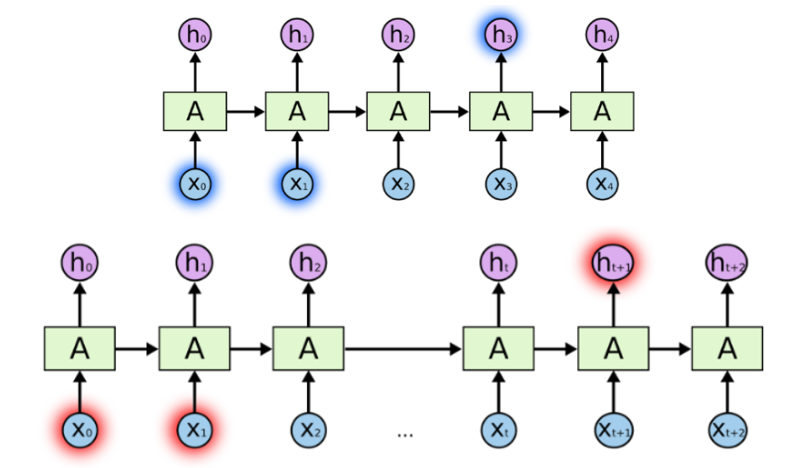
그런데 이러한 RNN에 치명적인 단점이 있는데, 인풋 데이터와 아웃풋이 멀어질수록 오래전 데이터 정보가 잘 반영되지 못한다는 점이다. 이는 역전파시에도 gradient가 점차 줄어 학습이 거의 돼지 않는 vanishing gradient problem을 야기한다. 이러한 문제를 해결하기 위해 LSTM이 등장한다.
RNN in NLP
자연어(natural language)는 단어 앞 뒤의 문맥을 함께 이해해야 정확한 의미 파악이 가능하다. 따라서 기존의 NN 모델 보다는 이전 데이터 정보를 보존하고, 이를 다음 출력에 반영하는 RNN이 순차적인 데이터인 자연어 처리에 적합하다고 할 수 있다.
▶RNN의 기본 구조
앞

RNN의 기본 구조는 위 그림과 같다.
activation function은 히든에서 아웃풋으로 갈때도, 히든에서 다음 히든으로 넘어갈때도 적용시켜야한다.
cf) tanh는 sigmoid에 비해 아웃풋 range가 넓고, gradient가 크게 나와 sequatial하게 진행되는 RNN에서 데이터 유실과 gradient vanshing 문제를 조금 방지해준다. 하지만 궁극적으로 데이터 유실과 gradient vanishing문제가 생겨 LSTM 모델이 나오게 된다.
bi RNN 히든을 양방향으로 sequation하게 줘서 기존 RNN이 히든이 깊어지면서 초기 데이터 정보가 약해지는 부분을 보완한다. 하지만 이 bi RNN도 중간에 정보가 날라가고 RNN의 근본적인 문제인 gradient vanishing 문제가 생긴다.
bptt
many-to-many의 경우 loss를 bp시키는 연산량이 너무 많아 bp를 뒤에 5개정도만 수행해주는 방법을 사용하기도 한다.
LSTM
최종 값(셀 스테이트)에 대한 정보를 히든스테이트와 매 시점의 인풋데이터로 계속 갱신해주자는 아이디어
forget gate 전 히든 데이터를 얼마나 반영할지를 시그모이드를 통해 구해서 셀스테이트에 반영해준다.
'ML & DL' 카테고리의 다른 글
| [강화학습] Lec.1 Introduction to Reinforcement learning (0) | 2020.01.19 |
|---|---|
| [NLP] Seq-to-Seq (0) | 2019.12.07 |
| [머신러닝]SVM(Support Vector Machine) by MIT (0) | 2019.11.16 |
| [머신러닝]Machine Learning(standford) 2강 - feature scaling/learning rate/polynomial regression (5) | 2019.11.01 |
| 텍스트 전처리(Boaz NLP 1팀) (0) | 2019.10.31 |



