Boaz 세션에서 다룬 발표 내용을 정리한 것 입니다
텍스트 데이터는 일반적인 데이터와 다르게 수치형이나 테이블형으로 표현되어 있지 않기에 분석을 위해 전처리를 해주어야 합니다. 그 전처리 방법에 대해 공부해 보겠습니다
1. 토큰화(Tokenization)
- 글을 단어나 문장 기준으로 나누어 토큰(token, 작은 덩어리)으로 바꾸는 과정
- corpus : 자연어 데이터 모음(단락형태), corpora(corpus 복수형)
- 구두점 특수문자 띄어쓰기 (ph.d, New York) 등 주의를 해야함
- 영어보다 한국어가 어려움 > 교착어라서 & 띄어쓰기가 영어만큼 엄격하지 않음

- 품사 태깅 : 토큰화 시킨 단어가 어떤 품사로 쓰였는지 보여주는 기능

2. 정제/정규화(Cleaning & Normalization)
- 정제 : 코퍼스로 부터 노이즈 데이터를 제거 > 불필요한, 빈도가 적거나, 의미없는 단어 제거
- 정규화 : 표현 방법이 다른 단어들을 통합시켜 같은 단어로 만들어줌 > Stemming & Lemmatization
3. Stemming & Lemmatization
- Stemming > 단어를 축약형으로 바꿔준다
- Lemmatization > 품사 정보를 보존한 기본형으로 바꿔준다

> Stemming이 그 단어 자체만 고려한다면 Lemmatization은 단어가 문장 속에서 어떤 품사로 쓰였는지
까지 고려함
> flies 가 주어졌을 때, stemming은 단어의 어근인 fly를 내놓는 반면, lemmatization은 flies가 날다,
파리 등 어떤 의미 인지 파악해서 이에 맞게 기본형으로 바꿔준다.
> Lemmatization 비교적 정확하지만 시간과 비용이 더 많이 든다. 둘 다 써도 된다!
4. 불용어(Stopword)
- 큰 의미가 없는 단어 토큰 > 분석에 있어 큰 도움이 되지 않는 단어
- 조사, 접속사 등이 해당할 수 있고, 직접 불용어 사전을 만들어 제거할 수 도 있다.
5. 정규표현식(Regular Expression)
소문자는 그 문자에 해당하는 표현식 대문자는 여집합
re.sub('[^a-zA-Z]',' ',text)
^ : not, 즉 영어가 아니면 공백으로 대체해라
7. 정수 인코딩
토큰화 및 위 작업이 완료된 글자들을 분석을 위해 숫자로 매핑해주는 것
>
8. 원핫인코딩
> 단어간의 관계나 유사성 파악 힘듬
9. subword segmentation
학습되지 않은 단어가 들어왔을 때! OOV(out of vocabulary)문제
단어 분리(subword segmentation)를 통해 대처
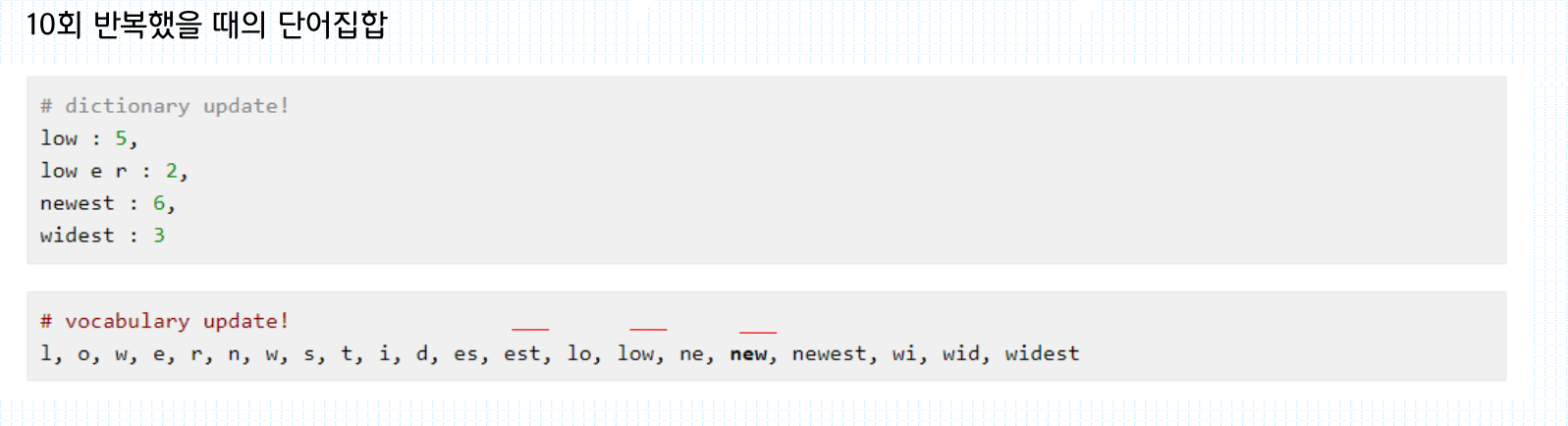
위 표처럼, low lower newest widest라는 단어가 학습되었을때 각 입력 단어들을 한 글자씩 분리해서
빈도 수가 가장 높은 알파벳 순으로 묶어 새로운 학습용 단어를 만든다 (ex. est, es, ne....)
vgg net
16~19 layer 와 3X3 field를 가짐
input 픽셀값에서 각 필셀 평균 RGB값을 빼서 학습 속도를 향상시킴
3x3 conv. layer를 사용한다
> 모든 방향을 고려하는 최소 단위
stride = 1 / padding = 1
maxpooling : 모든 conv. layer 뒤에 붙히지는 않는다
타 모델과 다르게 작은 필드를 사용하는 이유?
작은 필드를 여러번 사용하면서 (필드를 적용할때마다 렐루등 비선형성을 준다) 여러번 비선형성을 주고, 파라미터 수도 줄이는 효과가 있다
validation set accuracy 가 성능 향상을 멈출때 마다 learning rate를 10 배 감소시킴
총 3 번 감소 되었고 74 epochs(370K iteration) 에서 학습을 멈춤
'ML & DL' 카테고리의 다른 글
| [NLP] Seq-to-Seq (0) | 2019.12.07 |
|---|---|
| [딥러닝]RNN과 LSTM (0) | 2019.11.18 |
| [머신러닝]SVM(Support Vector Machine) by MIT (0) | 2019.11.16 |
| [머신러닝]Machine Learning(standford) 2강 - feature scaling/learning rate/polynomial regression (5) | 2019.11.01 |
| [머신러닝]Machine learning (stanford) 1강 - Gradient descent (0) | 2019.10.26 |



