Pytorch Architecture Practice(PAP) #1 U_Net
이번 포스팅은 파이토치로 image segmentation network 중 하나인 UNet을 구현하면서 코드를 하나씩 뜯어보겠습니다. UNet에 대한 이론은 다음 글을 참고해주세요 Wave U-Net . 구현에 사용할 데이터는 ISBI 2012 em image segmentation(http://brainiac2.mit.edu/isbi_challenge/home) 대회에서 사용한 이미지 데이터 셋을 사용했습니다.
전체 코드는 https://github.com/HyunLee103/Pytorch_practice/tree/master/Architecture/UNet 에 있으며, 한요섭 님의 코드를 참고하였습니다.
글에서는 코드 일부를 뜯어보며 파이토치가 어떻게 동작하는지 알아보겠습니다.
UNet Modeling

데이터 셋은 위 그림과 같이 input과 각 input에 해당하는 label이 총 30세트가 있다. 목적은 input data로 label에 가깝게 image segmentation하는 모델을 만드는 것이다.
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms,datasets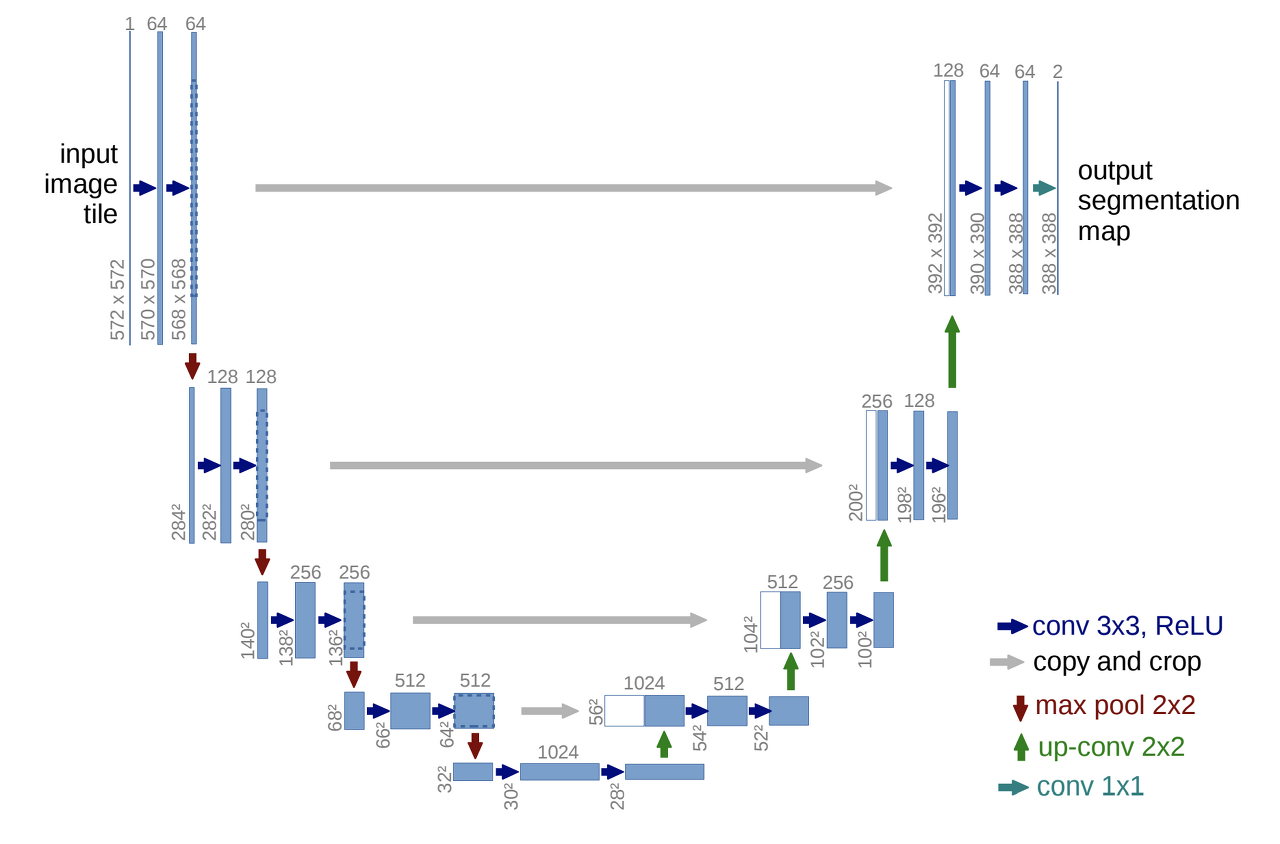
# 'nn.Module' 이라는 파이토치 base class를 상속받아서
# 사용자 정의 network 만들기
# UNet class가 instance로 할당될때 초기화되는 함수 __init__, 이 함수에서
# 네트워크에 사용될 layer들을 전부 self.net으로 선언
class UNet(nn.Module):
def __init__(self):
# super(subclass, self) : subclass에서 base class의 내용을 오버라이드해서 사용하고 싶을 때
super(UNet, self).__init__()
# 네트워크에서 반복적으로 사용되는 Conv + BatchNorm + Relu를 합쳐서 하나의 함수로 정의
def CBR2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True):
layers = []
layers += [nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
bias=bias)]
layers += [nn.BatchNorm2d(num_features=out_channels)]
layers += [nn.ReLU()]
cbr = nn.Sequential(*layers) # *으로 list unpacking
return cbr
# Contracting path
self.enc1_1 = CBR2d(in_channels=1, out_channels=64)
self.enc1_2 = CBR2d(in_channels=64, out_channels=64)
self.pool1 = nn.MaxPool2d(kernel_size=2)
self.enc2_1 = CBR2d(in_channels=64, out_channels=128)
self.enc2_2 = CBR2d(in_channels=128, out_channels=128)
self.pool2 = nn.MaxPool2d(kernel_size=2)
# Expansive path
self.dec5_1 = CBR2d(in_channels=1024, out_channels=512)
self.unpool4 = nn.ConvTranspose2d(in_channels=512, out_channels=512,
kernel_size=2, stride=2, padding=0, bias=True)
self.dec4_2 = CBR2d(in_channels=2 * 512, out_channels=512)
self.dec4_1 = CBR2d(in_channels=512, out_channels=256)
self.unpool3 = nn.ConvTranspose2d(in_channels=256, out_channels=256,
kernel_size=2, stride=2, padding=0, bias=True)
# __init__ 함수에서 선언한 layer들 연결해서 data propa flow 만들기
def forward(self, x):
enc1_1 = self.enc1_1(x)
enc1_2 = self.enc1_2(enc1_1)
pool1 = self.pool1(enc1_2)
생략
unpool1 = self.unpool1(dec2_1)
cat1 = torch.cat((unpool1, enc1_2), dim=1)
dec1_2 = self.dec1_2(cat1)
dec1_1 = self.dec1_1(dec1_2)
out = self.fc(dec1_1)
return out # data가 모든 layer를 거쳐서 나온 output 값Dataset & Transform
데이터가 흘러갈 네트워크를 선언했으니 데이터를 잘 처리해서 네트워크에 흘려보내주면 된다. 파이토치는 데이터를 불러오기 변환하는 과정을 Dataset class와 Transform class로 구현한다. 먼저 Dataset 부터 보자.
class Dataset(torch.utils.data.Dataset):
# torch.utils.data.Dataset 이라는 파이토치 base class를 상속받아
# 그 method인 __len__(), __getitem__()을 오버라이딩 해줘서
# 사용자 정의 Dataset class를 선언한다
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
lst_data = os.listdir(self.data_dir)
# 문자열 검사해서 'label'이 있으면 True
# 문자열 검사해서 'input'이 있으면 True
lst_label = [f for f in lst_data if f.startswith('label')]
lst_input = [f for f in lst_data if f.startswith('input')]
lst_label.sort()
lst_input.sort()
self.lst_label = lst_label
self.lst_input = lst_input
def __len__(self):
return len(self.lst_label)
# 여기가 데이터 load하는 파트
def __getitem__(self, index):
label = np.load(os.path.join(self.data_dir, self.lst_label[index]))
inputs = np.load(os.path.join(self.data_dir, self.lst_input[index]))
# normalize, 이미지는 0~255 값을 가지고 있어 이를 0~1사이로 scaling
label = label/255.0
inputs = inputs/255.0
label = label.astype(np.float32)
inputs = inputs.astype(np.float32)
# 인풋 데이터 차원이 2이면, 채널 축을 추가해줘야한다.
# 파이토치 인풋은 (batch, 채널, 행, 열)
if label.ndim == 2:
label = label[:,:,np.newaxis]
if inputs.ndim == 2:
inputs = inputs[:,:,np.newaxis]
data = {'input':inputs, 'label':label}
if self.transform:
data = self.transform(data)
# transform에 할당된 class 들이 호출되면서 __call__ 함수 실행
return data다음은 Transform인데, 이 부분은 휴리스틱하게 원하는 전처리를 해주면 된다. 일반적으로 데이터가 numpy 형태라면 tensor로 바꿔주고, 이미지의 경우 Flip(방향 뒤집기)을 통해 data augumentation 효과를 주기도 한다. 이 예제에서 데이터는 np 형태이고 이미지이므로 언급한 두 변환에 더해 정규화도 취해보자.
class ToTensor(object):
def __call__(self, data):
label, input = data['label'], data['input']
# numpy와 tensor의 배열 차원 순서가 다르다.
# numpy : (행, 열, 채널)
# tensor : (채널, 행, 열)
# 따라서 위 순서에 맞춰 transpose
label = label.transpose((2, 0, 1)).astype(np.float32)
input = input.transpose((2, 0, 1)).astype(np.float32)
# 이후 np를 tensor로 바꾸는 코드는 다음과 같이 간단하다.
data = {'label': torch.from_numpy(label), 'input': torch.from_numpy(input)}
return data
Training
## 하이퍼 파라미터 설정
lr = 1e-3
batch_size = 4
num_epoch = 100
data_dir = '/content/drive/My Drive/Colab Notebooks/파이토치/Architecture practice/UNet/data'
ckpt_dir = '/content/drive/My Drive/Colab Notebooks/파이토치/Architecture practice/UNet/checkpoint'
log_dir = '/content/drive/My Drive/Colab Notebooks/파이토치/Architecture practice/UNet/log'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# transform 적용해서 데이터 셋 불러오기
transform = transforms.Compose([Normalization(mean=0.5, std=0.5), RandomFlip(), ToTensor()])
dataset_train = Dataset(data_dir=os.path.join(data_dir,'train'),transform=transform)
# 불러온 데이터셋, 배치 size줘서 DataLoader 해주기
loader_train = DataLoader(dataset_train, batch_size = batch_size, shuffle=True)
# val set도 동일하게 진행
dataset_val = Dataset(data_dir=os.path.join(data_dir,'val'),transform = transform)
loader_val = DataLoader(dataset_val, batch_size=batch_size , shuffle=True)
# 네트워크 불러오기
net = UNet().to(device) # device : cpu or gpu
# loss 정의
fn_loss = nn.BCEWithLogitsLoss().to(device)
# Optimizer 정의
optim = torch.optim.Adam(net.parameters(), lr = lr )
# 기타 variables 설정
num_train = len(dataset_train)
num_val = len(dataset_val)
num_train_for_epoch = np.ceil(num_train/batch_size) # np.ceil : 소수점 반올림
num_val_for_epoch = np.ceil(num_val/batch_size)
# 기타 function 설정
fn_tonumpy = lambda x : x.to('cpu').detach().numpy().transpose(0,2,3,1) # device 위에 올라간 텐서를 detach 한 뒤 numpy로 변환
fn_denorm = lambda x, mean, std : (x * std) + mean
fn_classifier = lambda x : 1.0 * (x > 0.5) # threshold 0.5 기준으로 indicator function으로 classifier 구현
# Tensorbord
writer_train = SummaryWriter(log_dir=os.path.join(log_dir,'train'))
writer_val = SummaryWriter(log_dir = os.path.join(log_dir,'val'))# 네트워크 저장하기
# train을 마친 네트워크 저장
# net : 네트워크 파라미터, optim 두개를 dict 형태로 저장
def save(ckpt_dir,net,optim,epoch):
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
torch.save({'net':net.state_dict(),'optim':optim.state_dict()},'%s/model_epoch%d.pth'%(ckpt_dir,epoch))
# 네트워크 불러오기
def load(ckpt_dir,net,optim):
if not os.path.exists(ckpt_dir): # 저장된 네트워크가 없다면 인풋을 그대로 반환
epoch = 0
return net, optim, epoch
ckpt_lst = os.listdir(ckpt_dir) # ckpt_dir 아래 있는 모든 파일 리스트를 받아온다
ckpt_lst.sort(key = lambda f : int(''.join(filter(str,isdigit,f))))
dict_model = torch.load('%s/%s' % (ckpt_dir,ckpt_lst[-1]))
net.load_state_dict(dict_model['net'])
optim.load_state_dict(dict_model['optim'])
epoch = int(ckpt_lst[-1].split('epoch')[1].split('.pth')[0])
return net,optim,epoch
# 네트워크 학습시키기
start_epoch = 0
net, optim, start_epoch = load(ckpt_dir = ckpt_dir, net = net, optim = optim) # 저장된 네트워크 불러오기
for epoch in range(start_epoch+1,num_epoch +1):
net.train()
loss_arr = []
for batch, data in enumerate(loader_train,1): # 1은 뭐니 > index start point
# forward
label = data['label'].to(device) # 데이터 device로 올리기
inputs = data['input'].to(device)
output = net(inputs)
# backward
optim.zero_grad() # gradient 초기화
loss = fn_loss(output, label) # output과 label 사이의 loss 계산
loss.backward() # gradient backpropagation
optim.step() # backpropa 된 gradient를 이용해서 각 layer의 parameters update
# save loss
loss_arr += [loss.item()]
# tensorbord에 결과값들 저정하기
label = fn_tonumpy(label)
inputs = fn_tonumpy(fn_denorm(inputs,0.5,0.5))
output = fn_tonumpy(fn_classifier(output))
writer_train.add_image('label', label, num_train_for_epoch * (epoch - 1) + batch, dataformats='NHWC')
writer_train.add_image('input', inputs, num_train_for_epoch * (epoch - 1) + batch, dataformats='NHWC')
writer_train.add_image('output', output, num_train_for_epoch * (epoch - 1) + batch, dataformats='NHWC')
writer_train.add_scalar('loss', np.mean(loss_arr), epoch)
# validation
with torch.no_grad(): # validation 이기 때문에 backpropa 진행 x, 학습된 네트워크가 정답과 얼마나 가까운지 loss만 계산
net.eval() # 네트워크를 evaluation 용으로 선언
loss_arr = []
for batch, data in enumerate(loader_val,1):
# forward
label = data['label'].to(device)
inputs = data['input'].to(device)
output = net(inputs)
# loss
loss = fn_loss(output,label)
loss_arr += [loss.item()]
print('valid : epoch %04d / %04d | Batch %04d \ %04d | Loss %04d'%(epoch,num_epoch,batch,num_val_for_epoch,np.mean(loss_arr)))
# Tensorboard 저장하기
label = fn_tonumpy(label)
inputs = fn_tonumpy(fn_denorm(inputs, mean=0.5, std=0.5))
output = fn_tonumpy(fn_classifier(output))
writer_val.add_image('label', label, num_val_for_epoch * (epoch - 1) + batch, dataformats='NHWC')
writer_val.add_image('input', inputs, num_val_for_epoch * (epoch - 1) + batch, dataformats='NHWC')
writer_val.add_image('output', output, num_val_for_epoch * (epoch - 1) + batch, dataformats='NHWC')
writer_val.add_scalar('loss', np.mean(loss_arr), epoch)
# epoch이 끝날때 마다 네트워크 저장
save(ckpt_dir=ckpt_dir, net = net, optim = optim, epoch = epoch)
writer_train.close()
writer_val.close()Tensorbord

reference
'ML & DL' 카테고리의 다른 글
| [Pytorch] Pix2Pix 구현하기 (6) | 2020.05.09 |
|---|---|
| [Pytorch] DCGAN 밑바닥부터 구현하기 + 딥러닝 프레임워크 고도화 (4) | 2020.05.05 |
| [논문] Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks (2006) (0) | 2020.03.13 |
| [논문] Deep Neural Networks for Acoustic Modeling in Speech Recognition(IEEE, 2012) (0) | 2020.03.06 |
| [강화학습] Lec.2 Markov decision process(MDP) (0) | 2020.02.02 |


