IEEE에 2012년에 발표된, 토론토 대학, MS, 구글, IBM의 shared 논문 "Deep Neural Networks for Acoustic Modeling in Speech Recognition"을 공부하며, 정리한 글입니다. 모두의 연구소 음성인식 스터디의 정한길, 조용래 님의 발표자료를 참고했음을 먼저 밝힙니다.
Deep Neural Networks for Acoustic Modeling in Speech Recognition - Microsoft Research
Most current speech recognition systems use hidden Markov models (HMMs) to deal with the temporal variability of speech and Gaussian mixture models (GMMs) to determine how well each state of each HMM fits a frame or a short window of frames of coefficients
www.microsoft.com
ABSTRACT
대부분의 음성인식 시스템은, HMM으로 음성의 temporal variability을 처리하고, GMM으로 HMM의 각 state가 acoustic 인풋과 잘 fit 하게 모델링 해왔다. 그러나 최근 DNN이 GMM을 대신해 HMM의 Posterial Prob 을 계산하는데 성능이 GMM에 비해 압도적이다. 따라서 본 논문에서는 Acoustic modeling에서의 DNN의 성공적인 역할과 과정에 대해 알아본다.
HMM - DNN 을 같이 사용하는 하이브리드 모델에 대해 살펴 볼 것이다. DNN은 인풋으로 MFCC, PLC, Cepstral 등을 받아, HMM state의 Posterial Prob ~ P(state | Acoustuc input)을 아웃풋으로 출력한다.
Introduction
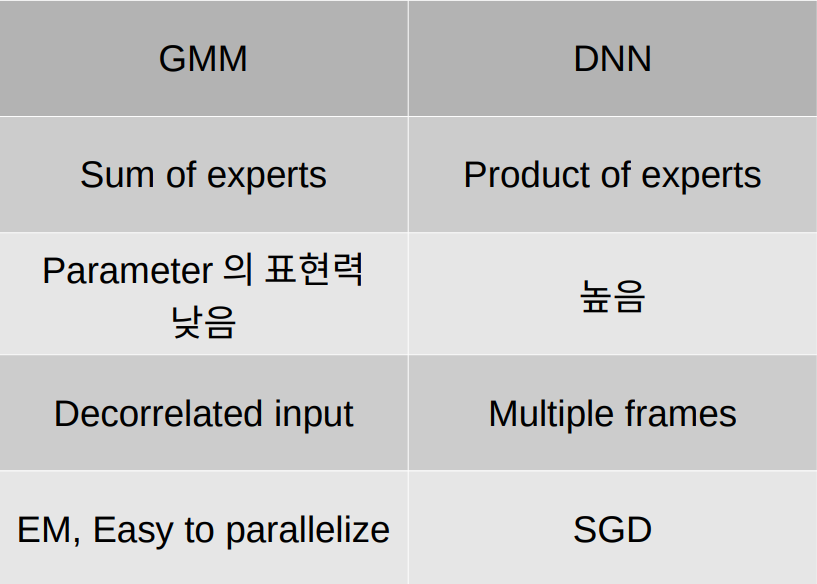
머신러닝 알고리즘이 ASR(automatic speech recognition)에서 기술적 우위에 있을 수 있었던 것은 HMM을 train 하기 위한 E-M 알고리즘(Expectation-Maximization) 때문이다. 다양한 GMM(HMM state - acoustic input 관계)을 사용해 음성인식을 real world task 로 만들었다. 이때 acoustic 인풋은 대체로 MFCCs, PLPs 을 사용했다. GMM은 HMM의 각 state값을 vector로 만들어 input을 sequential 받을 수 있다는 장점과 더불어, E-M 알고리즘 적용이 용이하다. 그래서 지금까지는 GMM의 속도와 Flexibility vs Overfitting 사이에 trade-off 등 GMM 성능 향상을 위한 연구가 활발하게 진행 되어왔다.
하지만, 이러한 GMM의 여러 장점과 많은 연구에도 불구하고, 다음과 같은 치명적인 단점이 생겨났고, GMM > DNN으로 대체함으로써 이를 해결했다.
"statistically inefficient for modeling data that lie on or near a nonlinear manifold in the data space"
다차원 데이터 공간에서 비선형 구조를 가지는 데이터를 GMM으로 모델링 하는것은 통계적으로 비효율적이다. DNN의 discriminative model로써의 특징과, 차원 변환의 관점에서 저 문장을 이해해보려 한다. GMM/DNN 모두 Frame 단위 음소 MFCC가 인풋으로 들어오는데, 이것의 분포보다는 어떤 phone에 해당할지(분류)가 궁금하므로, generative model(GMM) 보다는 discriminative model(DNN)을 쓰는게 parameter efficiency하다. 또한 DNN은 layer를 통과할 때 마다 input dimension을 계속 변화시키고, 고차원 공간에 데이터를 뿌리며 학습하기 때문에, 기존 train data에 없는 data가 들어왔을때 강하다. 반면 GMM은 정규분포로 가정을 하고 그 공간 안에서 데이터를 두고 E-M 알고리즘을 통해 확률을 최대화 시키기때문에 training data에 모델이 국한되는 한계가 있다.
10년전만 해도 DNN은 하드웨어와 테크닉의 한계로 가능성은 보였으나, 주목 받지 못했으나, 최근 컴퓨팅 파워와 머신러닝 알고리즘의 발달로 DNN은 이런 문제를 해결하고, large data/ large vocabularies 에 대한 Acoustic Modeling에서 GMM을 능가하는 퍼포먼스를 보였다.
Training Deep Neural Net
2012년에 나온 논문이라, batch norm이나 optimizer technic 등 다양한 딥러닝 기술이 정립되기 전이다. 그 당시에 문제가 되었고 고민중인 부분에 대한 서술과, 기본적인 딥러닝 학습 알고리즘에 대해 설명하고 있다. 따라서 이 부분은 부가 설명을 생략하겠다 :)
Generative pretraining
우리의 Task(MFCC가 어떤 phone에 속할지)를 모델링하기전에, 입력 데이터의 구조를 잘 모델링 하도록 하는 것 부터 하자는 아이디어! Generative pretraning > better starting point for discriminative fine-tuning ; 사실 이 pretrain은 요즘은 안 쓴다. 이 논문이 나온 2012년에는 딥러닝에 initializer가 없었다. 그래서 이러한 pretraining 기법을 사용했음(요즘 얘기하는 pretrain 개념과 조금 다르고, 지금은 딥러닝 테크닉의 발달로 사용하지 않는 기술이다) 간단하게 아이디어만 집고 넘어가자.
한 layer의 feature detector state로 그 다음 layet를 학습. 이렇게 generative하게 pretraining 되면, layer들이 discriminative fine-tuning 되기 좋은 상태가 된다. generative pretrain은 weight-space를 찾아주고 이는 discriminative fine-tuning 성능을 올리며 overfitting을 방지한다. 여기서는 Generative pretraining 모델로 Restricted Boltzmann Machine (RBM)을 사용한다.
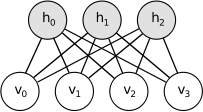
RBM은 일종의 근사 학습 알고리즘으로, Markov random field(MRF) 중 하나지만 다른 대부분의 MRF 와 조금 다르다(오토인코더의 일종으로 생각해도 좋다). 또한 Probabilistic model 이기 때문에 각 unit은 확률변수를 의미하고, 모델은 v,h의 joint prob를 의미한다. Joint prob은 아래와 같이 energy function으로 정의된다.
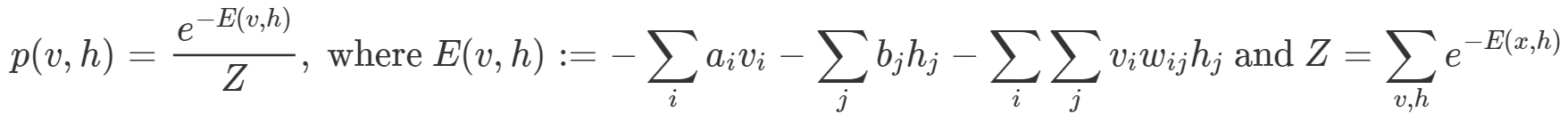
MODELING REAL-VALUED DATA

우리 input은 39차원 MFCC 이므로, 첫 RBM을 Gaussian-Bernoulli RBM으로 바꿔서 real-value에 대응하게 한다. 맨 처음 layer는 GRBM으로 그 위로 RBM을 쌓는다. 이때 input node는 freeze 시키고 히든 node를 위로 넘긴다.
DNN vs GMM
기존에 GMM은 diagonal covariance 모델을 사용하기에 각 feature간 독립임을 가정한다. 따라서 input이 rougly independent 해야 성능이 좋음, 따라서 각 구성요소가 roughly independent한 MFCC를 input으로 사용했다. 반면에 DNN은 데이터에 대한 분포 가정이 필요 없어, input이 indepent일 필요도 없으므로, MFCC까지 가지 않고 Mel-filter back를 통과시킨 Cepstral을 input으로 쓸 때 성능이 더 좋다.
DNN은 깊고 다양한 뉴럴넷 모델이 많이 만들어져 있으므로, 다양한 모델을 활용해도 된다.
'ML & DL' 카테고리의 다른 글
| [Pytorch] U-Net 밑바닥부터 구현하기 (5) | 2020.05.01 |
|---|---|
| [논문] Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks (2006) (0) | 2020.03.13 |
| [강화학습] Lec.2 Markov decision process(MDP) (0) | 2020.02.02 |
| [머신러닝] Boosting Algorithm (3) | 2020.01.26 |
| [강화학습] Lec.1 Introduction to Reinforcement learning (0) | 2020.01.19 |


