Pytorch Architecture Project #2 DCGAN
generative model 중 기본 모델로 불리는 DCGAN을 구현하고 정리했다. 기존에 코랩에서 모델 하나만 코딩할때는 파일 분할과 코드 고도화에 대한 생각없이 그냥 했었는데, 이번에 DCGAN을 구현하면서 해당 부분의 체계를 잡을 수 있었다. C에서 헤더파일로 필요한 함수 및 구조체를 분리하고 main에서 전부 불러와서 실행하는 느낌하고 좀 비슷하다.
DCGAN
paper : https://arxiv.org/pdf/1511.06434.pdf
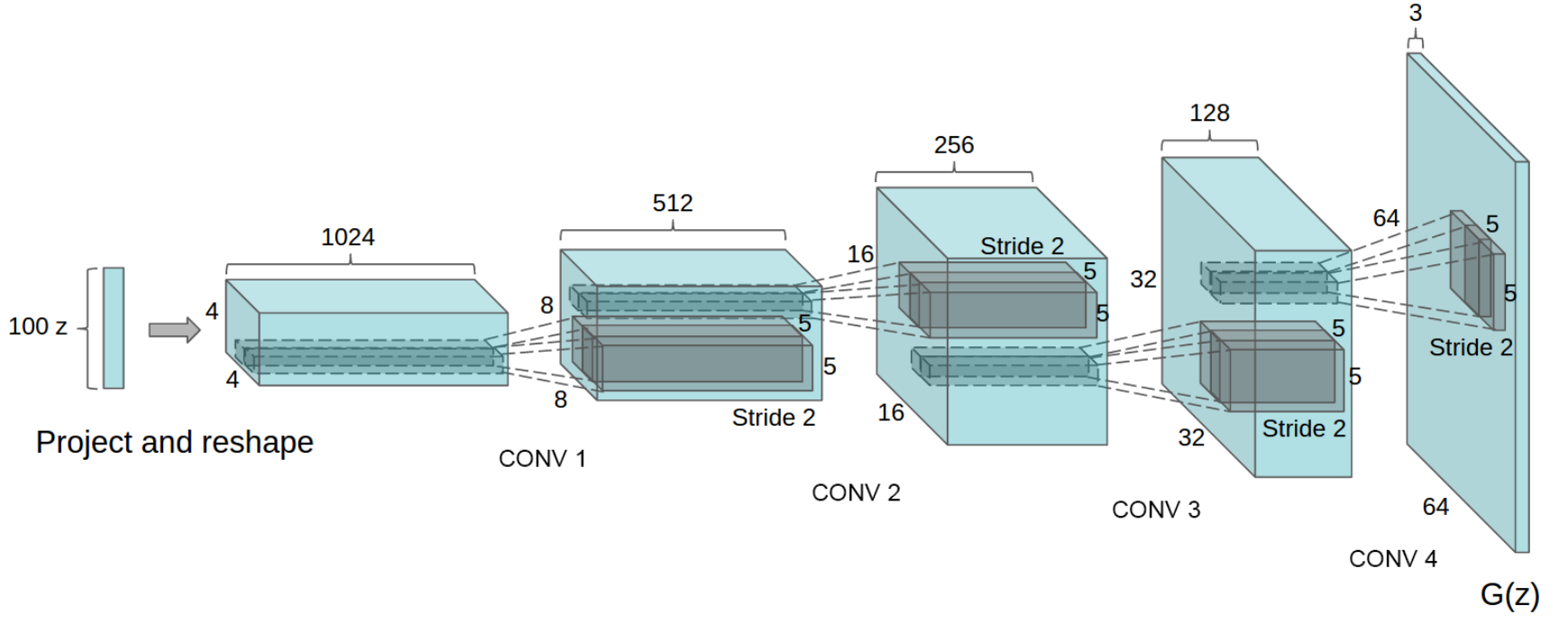
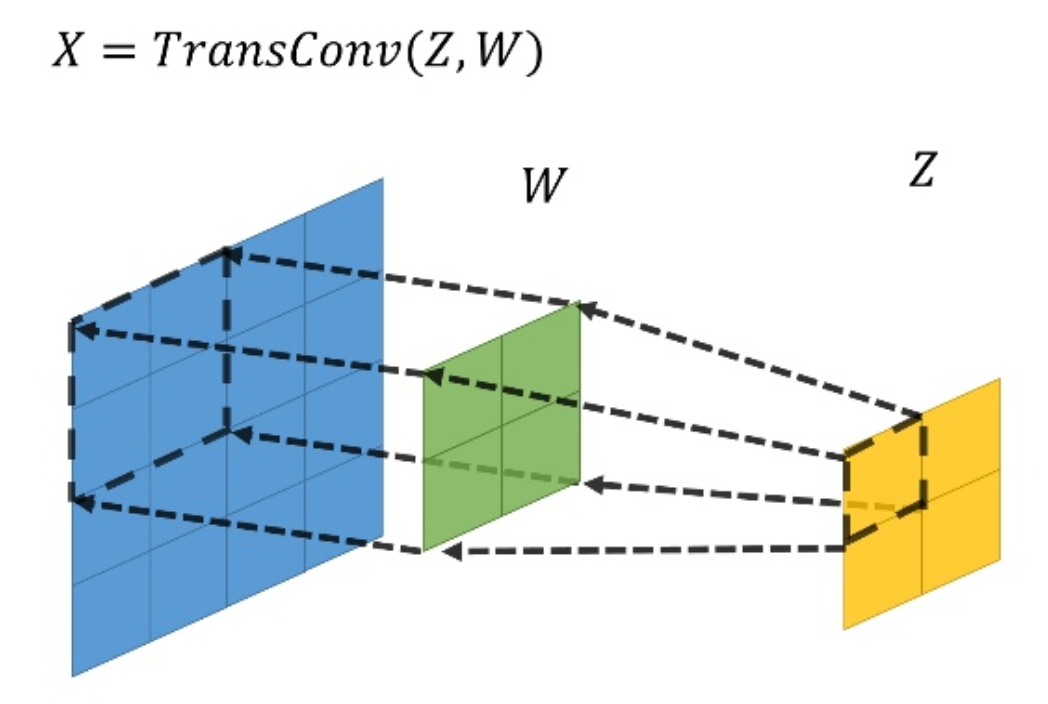
DCGAN은 generative model 중 하나로, generator와 discriminator 두 개의 네트워크가 서로 반대로 학습하는 구조를 가지고 있다. generator는 랜덤 노이즈 값을 받아 어떤 이미지를 생성하는 네트워크다. 위에 그림을 보면, Uniform 분포에서 랜덤 샘플한 100차원의 1x1 벡터가 generator 인풋으로 들어간다. 이를 z라고 한다. generator는 일반적인 CNN 구조와 다르게 layer를 거칠 수록 채널은 줄어들고 output size는 커진다. 따라서 일반적인 convolution의 역연산을 하는 Transposed Conv를 사용한다. Transposed Conv가 엄밀하게 수학적으로 Conv와 역연산 관계를 가지진 않는다. 하지만 공간을 넓히는 과정에서 convolution 개념을 사용하기에 딥러닝에서 많이 사용된다. 자세히 다루지는 않고 그림으로 이해하고 넘어가자.

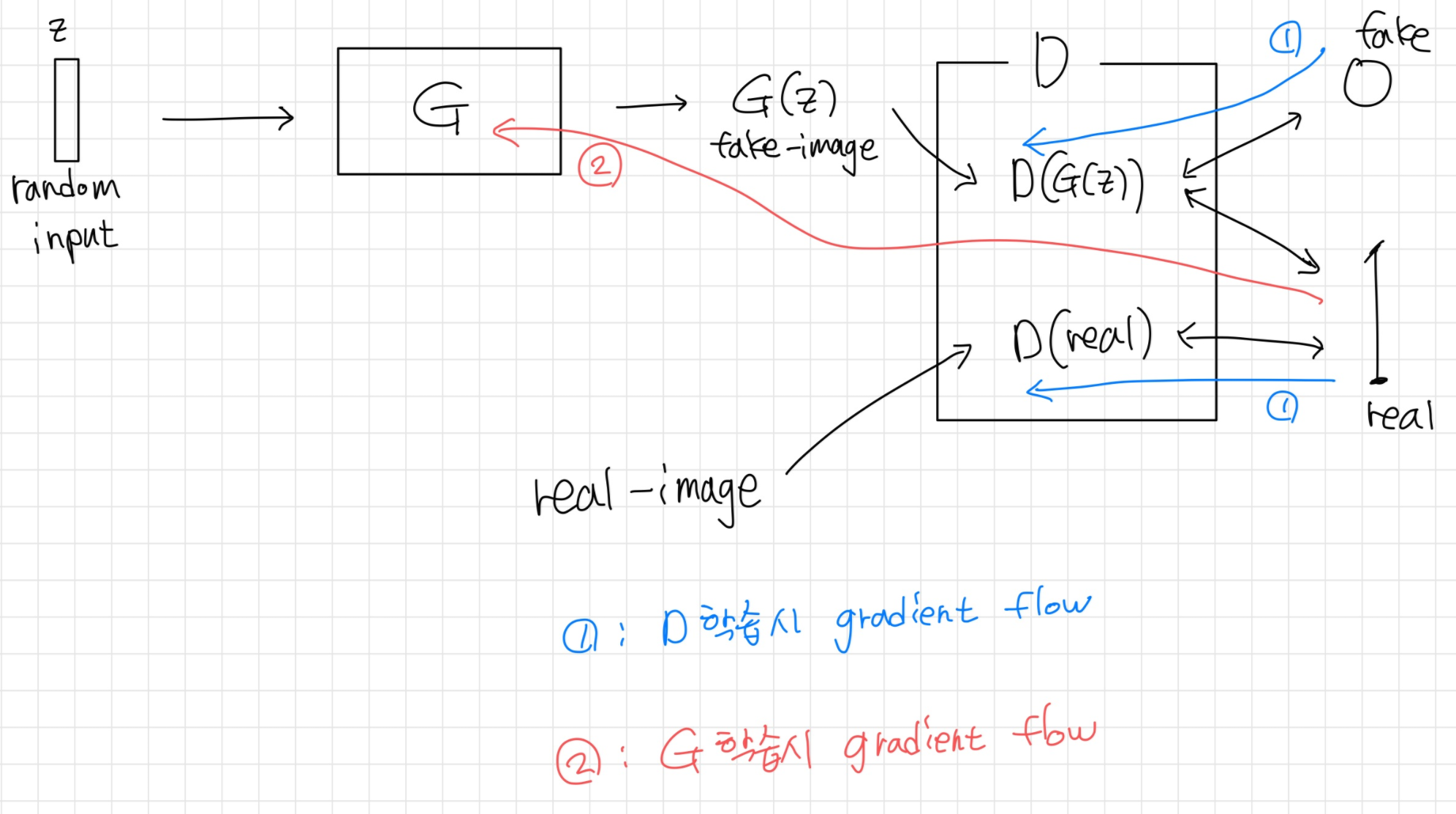
이렇게 G(generator)로 생성된 이미지는 fake-image가 된다. 그리고 D(discriminator)에 들어가 진짜인척 믿게 G를 학습하면 된다. D는 실제 이미지 데이터와 생성된 fake-image를 동시에 받아 각각을 실제는 실제로, 가짜는 가짜로 잘 구분하게 학습한다. 즉 G는 D가 헷갈려서 잘 못 맞출정도로 실제 이미지와 비슷한 fake-image를 생성하는 방향으로 학습을 하고, D는 G가 아무리 잘 만들어도 그게 가짜라고 구분하게 학습하므로 두 네트워크가 반대로 학습한다고 할 수 있다. 학습시 gradient의 흐름을 살펴보면 다음과 같다.
Implement

논문에 위와 같이 아키텍쳐 구현에 대한 가이드라인을 제시해주었다. 이를 따라가며 구현해보자. 다음은 최종 결과물이다. 우린 총 5개의 파이썬 파일로 DCGAN을 구현할거다.

dataset.py : 데이터를 불러와 전처리하고 변환하여 인풋 텐서로 만드는 과정을 class로 만든 파일
layer.py : 반복적으로 네트워크에서 사용되는 layer(batchnorm, relu, conv2d 등..)를 모아서 class로 만든 파일
model.py : 네트워크 구조를 구현한 파일
util.py : 자주 쓰이는 함수들을 따로 정의해 둔 파일
train.py : main 함수, 다른 파이썬 파일들을 모두 import해서 실제로 학습을 진행하는 파일
layer + model
우선 DCGAN에 필요한 두가지 네트워크, generator와 discriminator를 구현해보자.
가이드라인을 보면 generator에 batchnorm과 relu를 쓰라 했고, generator는 transposed conv로 연결되니까 해당 layer들을 모아서 layer.py에 DECBR2d 라는 class로 선언해주자.
class DECBR2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True, norm="bnorm", relu=0.0):
super().__init__()
layers = []
layers += [nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
bias=bias)]
if not norm is None:
if norm == "bnorm":
layers += [nn.BatchNorm2d(num_features=out_channels)]
elif norm == "inorm":
layers += [nn.InstanceNorm2d(num_features=out_channels)]
# 이따 Discriminator는 LeakyReLU 써야됨!
if not relu is None and relu >= 0.0:
layers += [nn.ReLU() if relu == 0 else nn.LeakyReLU(relu)]
self.cbr = nn.Sequential(*layers)
def forward(self, x):
return self.cbr(x)DECBR2d class를 이용해서 model.py에 generator를 구현해보자. 마지막 layer는 tanh이다.
class Generator(nn.Module):
def __init__(self, in_channels, out_channels,nker=128,norm="bnorm"):
super(Generator,self).__init__()
self.dec1 = DECBR2d(1 * in_channels, 8 * nker, kernel_size=4,stride=1,
padding=0,norm=norm,relu=0.0,bias=False)
self.dec2 = DECBR2d(8 * nker,4 * nker, kernel_size=4,stride=2,
padding=1, norm=norm,relu=0.0, bias=False)
self.dec3 = DECBR2d(4 * nker,2 * nker, kernel_size=4,stride=2,
padding=1, norm=norm,relu=0.0, bias=False)
self.dec4 = DECBR2d(2 * nker,1 * nker, kernel_size=4,stride=2,
padding=1, norm=norm,relu=0.0, bias=False)
self.dec5 = DECBR2d(1 * nker,out_channels, kernel_size=4,stride=2,
padding=1, norm=None,relu=None, bias=False)
def forward(self,x):
x = self.dec1(x)
x = self.dec2(x)
x = self.dec3(x)
x = self.dec4(x)
x = self.dec5(x)
x = torch.tanh(x)
return xDiscriminator는 generator와 정확히 반대로 짜면 된다. 가이드라인에 맞게 Conv, LeakyReLU, batchnorm 를 모아서 CBR2d class를 선언하자.
class CBR2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True, norm="bnorm", relu=0.0):
super().__init__()
layers = []
layers += [nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
bias=bias)]
if not norm is None:
if norm == "bnorm":
layers += [nn.BatchNorm2d(num_features=out_channels)]
elif norm == "inorm":
layers += [nn.InstanceNorm2d(num_features=out_channels)]
if not relu is None and relu >= 0.0:
layers += [nn.ReLU() if relu == 0 else nn.LeakyReLU(relu)]
self.cbr = nn.Sequential(*layers)
def forward(self, x):
return self.cbr(x)
class Discriminator(nn.Module):
def __init__(self, in_channels,out_channels,nker=64,norm='bnorm'):
super(Discriminator,self).__init__()
self.enc1 = CBR2d(1 * in_channels, 1 * nker, kernel_size=4,stride=2,
padding=1,norm=norm,relu=0.2,bias=False) # relu=0.2 > LekyLely
self.enc2 = CBR2d(1 * nker, 2 * nker, kernel_size=4,stride=2,
padding=1,norm=norm,relu=0.2,bias=False)
self.enc3 = CBR2d(2*nker, 4 * nker, kernel_size=4,stride=2,
padding=1,norm=norm,relu=0.2,bias=False)
self.enc4 = CBR2d(4 * nker, 8 * nker, kernel_size=4,stride=2,
padding=1,norm=norm,relu=0.2,bias=False)
self.enc5 = CBR2d(8 * nker, out_channels, kernel_size=4,stride=2,
padding=1,norm=None,relu=None,bias=False)
def forward(self,x):
x = self.enc1(x)
x = self.enc2(x)
x = self.enc3(x)
x = self.enc4(x)
x = self.enc5(x)
x = torch.sigmoid(x)
return x위와 동일하게 model.py에 Dicriminator를 선언해주자. 마지막 아웃풋 layer는 sigmoid(가이드 라인)
Dataset
Dataset class는 torch.utils.data.Dataset을 상속받아 해당 base class의 method인 __getitem__( )을 통해 데이터를 불러온다. 이후 transform class들을 따로 선언하여 raw data에 필요한 전처리와 변환을 취해준다.
class Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, transform=None, task=None, opts=None):
self.data_dir = data_dir
self.transform = transform
self.task = task
self.opts = opts
self.to_tensor = ToTensor() # 인풋값을 네트워크에 올리기위해 텐서로 변환하는 함수
lst_data = os.listdir(self.data_dir)
lst_data = [f for f in lst_data if f.endswith('jpg') | f.endswith('jpeg') | f.endswith('png')]
lst_data.sort()
self.lst_data = lst_data
def __len__(self):
return len(self.lst_data)
def __getitem__(self, index): # iterator 만들기
img = plt.imread(os.path.join(self.data_dir, self.lst_data[index]))
sz = img.shape
if img.ndim == 2:
img = img[:, :, np.newaxis]
if img.dtype == np.uint8:
img = img / 255.0
data = {'label': img}
if self.transform: # transform이 정의되었다면 변환 수행
data = self.transform(data)
data = self.to_tensor(data) # 텐서로
return dataDCGAN task에서는 ToTensor, Normalization, Resize 총 3개의 transform을 사용한다. 각각을 다음과 같이 class로 선언해주자.
class ToTensor(object):
def __call__(self, data):
for key, value in data.items():
value = value.transpose((2, 0, 1)).astype(np.float32)
data[key] = torch.from_numpy(value)
return data
class Normalization(object):
def __init__(self, mean=0.5, std=0.5):
self.mean = mean
self.std = std
def __call__(self, data):
for key, value in data.items():
data[key] = (value - self.mean) / self.std
return data
# DCGAN에 사용할 selanA image data가 DCGAN 모델의 generator output인 64x64와 맞지 않으므로
# resize 해주는 transform class 선언
class Resize(object):
def __init__(self,shape):
self.shape = shape
def __call__(self, data):
for key, value in data.items():
data[key] = resize(value, output_shape=(self.shape[0],self.shape[1],
self.shape[2]))
return dataUtil
유틸에는 메인 함수에서 필요한 함수들을 미리 구현해둔다. 여기서는 다음 총 4개의 함수를 선언한다.
def set_requires_grad(nets, requires_grad=False)backprop시에 특정 네트워크 gradient 추적여부를 결정하는 함수, 첫번째 param인 nets의 gradient 추적 여부를 requires_grad = True / False로 결정한다.
def init_weights(net, init_type='normal', init_gain=0.02)' All weights were initialized from a zero-centered Normal distribution with standard deviation 0.02. ' _ DCGAN p.3
두번째는 논문에 나온 위 문장을 적용해주기 위한 함수. 네트워크의 weight를 N(0, 0.02)로 초기화한다.
def save(ckpt_dir, netG, netD, optimG, optimD, epoch):세번째는 학습 중 네트워크를 저장하기 위한 save 함수, DCGAN은 네트워크가 2개(G, D)이므로 각각 netG, optimG, netD, optimD 를 저장한다.
def load(ckpt_dir, netG, netD, optimG,optimD):마지막은 save로 저장한 네트워크를 불러오는 load 함수, train 시킨 네트워크를 test할 때나, 중간에 train을 멈춰서 이어서 할 때 사용한다.
자세한 util 함수 내용은 생략하겠다. (github을 참고해주세요!!)
Train
드디어 학습을 수행하는 메인 파일이다. 여기서는 위에서 선언한 파이썬 파일들을 전부 import 하여 필요한 함수나 class들을 사용한다.
1. Parser로 하이퍼 파라미터 받기
parser는 파이썬 파일을 터미널에서 실행할 때, 리눅스 커맨드 처럼 argument를 줄 수 있게 코드를 고도화 하는 방법이다. 예를 들어 다음과 같이 parser를 정의하고
parser.add_argument("--log_dir", default="./log", type=str, dest="log_dir")
parser.add_argument("--result_dir", default="./result", type=str, dest="result_dir")
해당 parser를 입력으로 받아 하이퍼 파라미터를 다음과 같이 선언하면
args = parser.parse_args()
log_dir = args.log_dir
result_dir = args.result_dir다음과 같이 터미널에서 해당 파이썬 파일의 하이퍼 파라미터를 parser argument로 지정해주며 실행할 수 있다.
DCGAN에 필요한 하이퍼 파라미터들을 받아보자.
## Parser 생성하기
parser = argparse.ArgumentParser(description="DCGAN modeling",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--mode", default="train", choices=["train", "test"], type=str, dest="mode")
parser.add_argument("--train_continue", default="off", choices=["on", "off"], type=str, dest="train_continue")
parser.add_argument("--lr", default=2e-4, type=float, dest="lr")
parser.add_argument("--batch_size", default=128, type=int, dest="batch_size")
parser.add_argument("--num_epoch", default=100, type=int, dest="num_epoch")
parser.add_argument("--data_dir", default="./datasets/BSR/BSDS500/data/images", type=str, dest="data_dir")
parser.add_argument("--ckpt_dir", default="./checkpoint", type=str, dest="ckpt_dir")
parser.add_argument("--log_dir", default="./log", type=str, dest="log_dir")
parser.add_argument("--result_dir", default="./result", type=str, dest="result_dir")
parser.add_argument("--task", default="DCGAN", choices=['DCGAN'], type=str, dest="task")
parser.add_argument('--opts', nargs='+', default=['bilinear', 4.0, 0], dest='opts')
parser.add_argument("--ny", default=64, type=int, dest="ny") # input data shape
parser.add_argument("--nx", default=64, type=int, dest="nx") # input data shape
parser.add_argument("--nch", default=3, type=int, dest="nch") # input data shape
parser.add_argument("--nker", default=128, type=int, dest="nker") # 네트워크 커널 size
parser.add_argument("--network", default="DCGAN", choices=["unet", "hourglass", "resnet", "srresnet",'DCGAN'], type=str, dest="network")
parser.add_argument("--learning_type", default="plain", choices=["plain", "residual"], type=str, dest="learning_type")
args = parser.parse_args()
## 트레이닝 파라메터 설정하기
mode = args.mode
train_continue = args.train_continue
lr = args.lr
batch_size = args.batch_size
num_epoch = args.num_epoch
data_dir = args.data_dir
ckpt_dir = args.ckpt_dir
log_dir = args.log_dir
result_dir = args.result_dir
task = args.task
opts = [args.opts[0], np.asarray(args.opts[1:]).astype(np.float)]
ny = args.ny
nx = args.nx
nch = args.nch
nker = args.nker
network = args.network
learning_type = args.learning_type다음은 torch.device를 설정해준다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
2. Directory, DataLoader, 네트워크 선언하기
생성된 이미지가 저장 될 directory를 생성하자.
result_dir_train = os.path.join(result_dir, 'train')
result_dir_test = os.path.join(result_dir, 'test')
if not os.path.exists(result_dir_train):
os.makedirs(os.path.join(result_dir_train, 'png'))
if not os.path.exists(result_dir_test):
os.makedirs(os.path.join(result_dir_test, 'png'))다음은 Dataset class 이용해서 데이터 불러오기~
if mode == 'train':
transform_train = transforms.Compose([Resize(shape=(ny,nx,nch)), Normalization(mean=0.5,std=0.5)]) # generator output인 tanh(-1~1) 값과
# D input scale을 맞춰주기 위해 normalize
dataset_train = Dataset(data_dir=os.path.join(data_dir), transform=transform_train, task=task, opts=opts)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=8)
mode == 'train'인 이유는, 생성모델에서 test시에 데이터셋을 불러올 필요가 없기 때문이다. 랜덤 벡터로 부터 generator가 생성한 이미지만 확인하면 된다. train 할 때는 Discriminator에 들어갈 real-image(label)가 필요하기 때문에 위와 같이 데이터를 불러와야 한다.
그리고 네트워크에 필요한 것들 선언하자.
## 네트워크 선언
if network == "DCGAN":
netG = Generator(in_channels=100,out_channels=nch,nker=nker).to(device)
netD = Discriminator(in_channels=nch,out_channels=1,nker=nker).to(device)
# 네트워크 가중치를 정규분포, std 0.02로 초기화
init_weights(netG,init_type='normal',init_gain=0.02)
init_weights(netD,init_type='normal',init_gain=0.02)
## 손실함수 선언
fn_loss = nn.BCELoss().to(device)
## Optimizer 선언
## 하나의 network에 하나의 optimizer가 필요, GAN은 네트워크가 두개 이므로 optimizer도 두개 필요
optimG = torch.optim.Adam(netG.parameters(), lr=lr, betas=(0.5,0.999)) # 논문에 맞게 Adam beta term을 조정 해줘야함
optimD = torch.optim.Adam(netD.parameters(), lr=lr,betas=(0.5,0.999))
## 그밖에 부수적인 functions 설정하기
fn_tonumpy = lambda x: x.to('cpu').detach().numpy().transpose(0, 2, 3, 1)
fn_denorm = lambda x, mean, std: (x * std) + mean
fn_class = lambda x: 1.0 * (x > 0.5)
cmap = None
3. 드디어 학습!!
if mode == 'train': # else : 'test'
if train_continue == "on": # 이어서 학습할때 on, 처음 학습 시킬때는 off
netG,netD, optimG,optimD, st_epoch = load(ckpt_dir=ckpt_dir, netG=netG,netD=netD, optimG=optimG,optimD=optimD)
for epoch in range(st_epoch + 1, num_epoch + 1):
netG.train() # 사용할 네트워크를 train 모드로 설정
netD.train() # 사용할 네트워크를 train 모드로 설정
loss_G_train= []
loss_D_real_train = []
loss_D_fake_train = [] # D(G(z))
for batch, data in enumerate(loader_train, 1): # loader_train에는 real-image data가 들어있다.
# forward pass
label = data['label'].to(device) # label : 실제이미지 data, device로 올리기 > D의 real 파트 인풋
input = torch.randn(label.shape[0],100,1,1).to(device) # generator 인풋은 유니폼 분포에서 랜덤 샘플된 100차원 벡터
# label.shape[0] : batch_size, 100 : ch , 1 : H, 1 : W
output = netG(input) # 위에서 생성한 noise input을 generator에 넣어 하나의 이미지 생성
# backward pass
# backprop도 두 네트워크 각각 해줘야 한다.
# Discriminator backprop
set_requires_grad(netD,True) # netD(Discriminator)의 모든 파라미터 연산을 추적해 gradient를 계산한다.
optimD.zero_grad() # gradient 초기화
pred_real = netD(label) # 진짜 이미지를 Discriminator에 통과시킨다. 이 결과가 True(1)를 가지게 D를 학습
pred_fake = netD(output.detach()) # output = netG(input), 즉 generator로 생성된 가짜 이미지를 D에 넣는다.
# 이 결과를 False(0)로 구분하게 D를 학습
# detach()는 G(z)-output을 그대로 넣으면 Generator까지 gradient가 흘러가기때문에
# 이를 분리해주기 위해 사용한다.
# D의 loss는 가짜이미지와 진짜이미지를 잘 구분하게 형성되어야 한다.
# 즉 G로 만들어진 가짜이미지는 False(0)으로 진짜 이미지는 True(1)로 타겟을 주고 loss를 구한다
loss_D_real = fn_loss(pred_real,torch.ones_like(pred_real))
loss_D_fake = fn_loss(pred_fake,torch.zeros_like(pred_fake))
loss_D = 0.5 * (loss_D_fake + loss_D_real)
loss_D.backward() # gradient backprop
optimD.step() # gradient update
# Generator backprop
set_requires_grad(netD,False) # generator를 학습할땐, discriminator는 고정한다. 따라서 required_grad = False
optimG.zero_grad() # gradient 초기화
pred_fake = netD(output)
loss_G = fn_loss(pred_fake,torch.ones_like(pred_fake)) # generator는 생성한 가짜 이미지가 진짜(True,1)로 분류되게 학습해야한다.
loss_G.backward() # gradient backprop
optimG.step() # gradient update
# 손실함수 계산
loss_G_train += [loss_G.item()]
loss_D_real_train += [loss_D_real.item()]
loss_D_fake_train += [loss_D_fake.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | G_LOSS %.4f | D_fake_LOSS %.4f | D_real_LOSS %.4f " %
(epoch, num_epoch, batch, num_batch_train, np.mean(loss_G_train), np.mean(loss_D_fake_train),np.mean(loss_D_real_train)))
if batch % 10 == 0:
# Tensorboard 저장하기
output = fn_tonumpy(fn_denorm(output,mean=0.5,std=0.5)).squeeze() # generator로 생성된 output은 마지막 layer에 tanh를 거치며 normalize된다.
# 따라서 denorm을 통해 복원
id = num_batch_train * (epoch - 1) + batch
plt.imsave(os.path.join(result_dir_train, 'png', '%04d_output.png' % id), output[0].squeeze(), cmap=cmap)
writer_train.add_image('output', output, id, dataformats='NHWC')
writer_train.add_scalar('loss_G', np.mean(loss_G_train), epoch)
writer_train.add_scalar('loss_D_fake', np.mean(loss_D_fake_train), epoch)
writer_train.add_scalar('loss_D_real', np.mean(loss_D_real_train), epoch)
# generative model은 unsupervised-learning이기 때문에, val 부분이 없다.
if epoch % 2 == 0: # epoch 2번마다 네트워크 checkpoint 저장
save(ckpt_dir=ckpt_dir, netG=netG, netD = netD, optimG=optimG, optimD=optimD, epoch=epoch)
writer_train.close() # tensorboard 닫기테스트는 위 코드에서 else 부분을 다음과 같이 짜면 된다.
# TEST MODE
else:
netG, netD, optimG, optimD, st_epoch = load(ckpt_dir=ckpt_dir, netG=netG, netD = netD, optimG=optimG, optimD = optimD)
with torch.no_grad():
netG.eval() # generative model은 test에서 Generator net만 사용한다. 왜냐면! generator로 얼마나 이미지가 잘 생성되었는지 보면 되므로
# 따라서 netG만 eval 모드로 해주면 된다. 따로 test loss는 없다
# input은 유니폼 분포의 랜덤 샘플 벡터
input = torch.randn(batch_size,100,1,1).to(device)
output = netG(input)
output = fn_tonumpy(fn_denorm(output, mean=0.5,std=0.5)) # generator의 아웃풋이 tanh로 normalize 되었으므로 denorm
for j in range(output.shape[0]):
id = j
output_ = output[j]
plt.imsave(os.path.join(result_dir_test, 'png', '%04d_output.png' % id), output_, cmap=cmap)
reference
'ML & DL' 카테고리의 다른 글
| [DL] Spectral Normalization (0) | 2020.06.04 |
|---|---|
| [Pytorch] Pix2Pix 구현하기 (6) | 2020.05.09 |
| [Pytorch] U-Net 밑바닥부터 구현하기 (5) | 2020.05.01 |
| [논문] Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks (2006) (0) | 2020.03.13 |
| [논문] Deep Neural Networks for Acoustic Modeling in Speech Recognition(IEEE, 2012) (0) | 2020.03.06 |


