2020년 2월에 발표된 따끈따끈한 논문입니다. Music style transform 프로젝트 중 한 task인 audio source separation을 위해 공부한 논문 중 하나입니다. 논문 링크 : https://arxiv.org/pdf/2002.07016v1.pdf
Introduction
세상의 많은 악기와 소리는 고유의 timbral qualities(음색)를 가지고 있다. 소프라노 가수와 트럼펫은 다른 카테고리로 분류되지만 비슷한 frequency를 가진다. 모델이 이러한 관계에 대해 인지한다면 각 악기의 특성을 반영한 seperation을 할 수 있을 것이다.
이 논문의 아이디어는 Meta-learning과 AutoML으로 부터 나왔다. 목표는 특정 악기의 뉘앙스를 반영하는 해당 악기에 특화된 정밀한 모델을 만드는 것이다.
이런 모델을 직접 만드는 대신, 이 파라미터를 예측하는 generator를 학습시키고 해당 파라미터를 이용한 extractor로 audio source separation을 달성한다.

위 그림이 전체 아키텍쳐이다. 파란 부분은 extractor(masking TCN)에 들어갈 특정 악기의 weights를 예측하는 parameter generator이고, 분홍 부분은 generator가 만들어준 weight를 extractor가 이용해 해당 악기를 전체 오디오 소스로 부터 분리한다.
Contribution
1. network generating Network(generator)를 적용
2. 성능 좋고 빠르고 단순하다
3. conv-TasNet에 몇가지 개선사항을 언급, SOTA 찍음
Extractor Model
Generator로 부터 parameter(weight)를 받아 audio source separation을 수행하는 Extractor는 Conv-TasNet(Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation,Yi Luo et al. IEEE)에 기반을 두고 있다. Spectrogram이 아닌 waveform 단에서 separation을 진행한다. 이 time domain에 기반한 Extractor는 다음의 세 파트로 나뉜다.

1) Encoder : 1D Conv 적용해서 mixture waveform의 조각들을 high-dim 표현으로 변환한다.
2) Masking TCN(Temporal convolution network) : 학습된 표현안에 타겟 영역을 indentify하기 위한 곱연산 함수
3) Decoder : 1D inverse Conv, separated waveform을 타겟 오디오 소스에 맞춰 reconstruct
' The use of an intermediate representation overcomes the difficulty of working with high resolution in the time dimension (tens of thousands samples per second) without the disadvantages of compressing the data via an unlearned transformation, such as a mel spectrogram '
저 intermediate representation의 사용이 mel-spectrogram 같이 학습되지 않은 변환으로 생기는 데이터 압축의 단점없이 타임 도메인에서의 고해상도 작업의 어려움을 극복하게 한다. 흠.. intermediate representation이게 위에서 얘기한 인코딩 된 걸 말하는 것 같고, frequency domain(spectrogram)으로 넘기지 않고 time domain(waveform)에서도 1D Conv를 통해 고차원 정보를 추출할 수 있다고 말하는 듯 하다.
1) encoder와 3) decoder가 source-agnositc이고 모든 sources/instruments에 대해 동일한 반면, masking network는 source-specific 정보를 가지고 있어(generator가 weight를 주니까?!) sources/instruments 마다 다른 구조를 갖게 된다.
Meta-learning Extractor Parameters(generator)
Generator는 Extractor 중 Masking TCN에 사용 될 파라미터(weight)를 예측한다. TCN의 k번째 Network의 파라미터를 예측하는 Generator 함수는 다음과 같이 정의한다.
$\theta _k := W_kP_ke_i$
$e_i \in \mathbb{R}^{M}$
e는 i 번째 악기에 대한 임배딩 원핫벡터 값
$P_k \in \mathbb{R}^{M^{'}\times M }$
$W_k \in \mathbb{R}^{\left | \theta_k \right |\timesM}$
W, P는 학습가능한 linear function, 행렬 형태이다.
ADAPTATIONS FOR TIME-DOMAIN MUSIC SOURCE SEPARATION
Conv-TasNet 아키텍쳐 개선점들에 대해 알아보자
1. multi stage architecture

예측 시그널의 resolution이 이전 단의 정보를 반영하며 더 정확해지는 것을 알 수 있다. time-dimension을 동일하게 유지하기 위해 매 stage마다 인코더 stride를 조절했다.
2. Auxiliary loss functions
학습과정의 성능 향상을 위해 다음 3개의 보조 Loss를 도입한다.
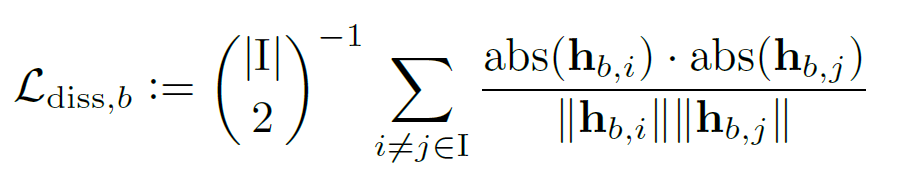
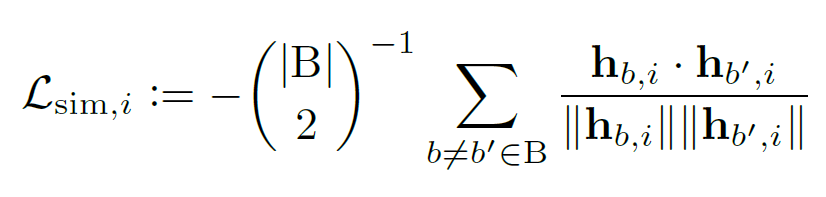
+Reconstruction Loss : This loss increases the SI-SNR between the mixture signal s
3. strong encoder

인코더에 1D Conv 뿐만 아니라 STFT 인풋을 줘서, input signal에 대한 더 distinct한 feature를 잡아낸다.
디코더는 인코더 과정과 매칭되게 구성한다.
The decoder uses a similar architecture to match the capacity of the encoder: after a transformation by Conv-ReLU, the vector is split and put to multiple transposed 1-D convolutions with the same kernel sizes as in the encoder. Finally, the estimated signal s_i is the sum of these outputs
Experiements
MUSDB18 데이터 셋 활용, 해당 데이터 셋은 음원과 각 음원에 대한 vocal, drum, bass, other 음원이 라벨링 되어 존재한다. 8초씩 random cut하고 각 음원에 대해 0.75 ~ 1.25 범위로 amplitude를 random scale 해 data augmentation 역할을 수행한다.
'Paper' 카테고리의 다른 글
| [추천시스템] Factorization Machine & FFM (0) | 2020.05.26 |
|---|---|
| [논문] A Universal Music Translation Network(2018) (0) | 2020.05.05 |
| [논문] Wave U-Net : A Multi-Scale Neural Network for End-to-End Audio Source Separation(Daniel et al. 2018) (0) | 2020.03.30 |
| [논문] WaveNet - A Generative Model for Raw Audio (0) | 2020.03.23 |
| [논문] Symbolic Music Genre Transfer with CycleGAN (ETH Zurich, 2018) (0) | 2020.03.23 |


