Music style transfer를 주제로 논문을 이것 저것 읽어보고 있었는데 계속해서 WaveNet이라는 이름이 등장해서 읽게 되었습니다. 2016년에 구글 딥마인드에서 발표한 waveform을 생성하는 generative model 입니다.
original papar : https://arxiv.org/pdf/1609.03499.pdf
ABSTRACT
Audio waveform을 generate 하는 모델. 확률기반의 autoregressive model(AR)이다. wavefrom을 결합확률분포로 표현하고, 이를 conv layer를 쌓아서 모델링하겠다는 아이디어.
Introduction
오디오 신호의 long-range temporal dependency를 해결하기 위해 dilated causal convolution을 제안하여 네트워크의 receptive fields를 넓혔다. WaveNe은 일반적이고 유연한 오디오 생성 모델로 TTS, 음악, voice conversion 등 다양한 분야에 응용이 가능할 것 이다.
WaveNet
WaveNet은 t 시점의 오디오 샘플을 t-1 시점까지의 샘플들의 조건부 분포로 모델링한다. 수식은 다음과 같다.
$p(x) = \prod_{t=1}^{T}p(x_t | x_1, ... ,x_{t-1})$
이는 특정 시점의 아웃풋을 계산할때 이전 시점의 인풋 데이터값을 보겠다는 의미이다. WaveNet은 위와 같은 조건부 분포를 Conv layer를 쌓아서 모델링한다. 네트워크에 pooling layer는 없고 input, output 차원이 동일하다. output에는 softmax를 취해 multinomial classification 문제로 다룬다. 최적화는 MLE를 사용한다. (다항분포 MLE -> minimize negative-log-likelihood -> minimize cross-entropy)
Dilated causal convolution
Dilated causal convolution은 dilation과 causal 두 개념이 같이 사용된 Conv 네트워크 구조다. 우선 dilation 은 Conv의 receptive field는 넓히면서 연산량은 크게 증가시키지 않는 방법이다.

위 그림을 보면 filter size는 3x3으로 유지하면서 receptive field는 넓히지만 sparse하게 연산량은 증가시키지 않는다. 앞서 언급했듯이 오디오 신호는 long-range temporal dependency가 있기 때문에 매우 넓은 receptive field가 필요하다. Causal Conv는 특정 시점을 연산하기 위해 이전 시점 데이터만을 이용하는 것을 의미한다. 이 둘을 같이 사용하면 다음과 같은 Dilated causal convolution 네트워크가 된다.

이 논문에서는 dilation을 1(, 2, 4, ..., 512) X3 만큼 주어서 총 30개 layer를 쌓는다.

softmax
아웃풋(조건부 확률)을 모델링 하는데 있어서, softmax 분포를 사용. 즉 mutinomial logistic regression 문제로 생각한다. 이러한 categorical distribution은 형태에 대한 가정이 없기 때문에 flexible하다는 장점이 있다. 대부분의 audio 신호는 16-bit로 quantization, 이를 softmax로 표현하려면 sample마다 65536개의 아웃풋이 필요하다. 즉 65536차원의 softmax 분포를 연산해야돼서 연산량이 너무 많다. 따라서 8-bit quantization sample(256개)을 사용, mu-law companding을 적용해 non-lineat하게하여 quatization 8-bit이지만 꽤 좋은 성능을 보이게 한다. 결국 우린 256개의 discrete한 값 중에 아웃풋이 어떤값으로 분류될지 그 확률(softmax)을 계산하게 된다.
다음과 같은 수식으로 mu-law companding을 하여, 256개의 value로 quantize 한다.
$f(x_t) = sign(x_t)\frac{\ln (1 + \mu \left | x_t \right |)}{(1+\mu)}$
$where, -1 < x_t < 1 , \mu = 255$
Gated Activation units
dialted Conv 뒤에 gate network 사용해서 다음 layer로 전달할 비율을 조절해준다.
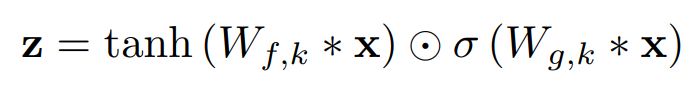
Residual & skip connection
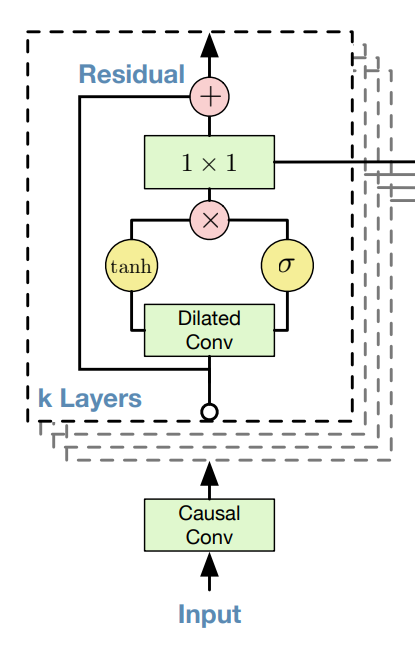
깊은 네트워크에서의 수렴성과 학습 속도를 위해 residual term을 추가해준다.

위 그림으로 전체과정을 보면, input signal이 들어가서 dilated conv -> Gated activation -> 1x1 conv + residual을 거쳐 하나는 그 다음 layer로 하나는 오른쪽으로 빼서 skip connection으로 꺼낸다. 이때 1x1 Conv filter를 256개를 줘서 아웃풋을 256(8bit)로 맞춰준다. 이 논문에서는 총 30개의 layer를 쌓는다고 했으니 Residual block도 30개가 있고, skip connection으로 빠져나온 벡터도 총 30개다. 이를 전부 더해서 마지막에 softmax를 취해 256개의 값 중 어디로 assign 될 확률이 가장 높은지 구한다. 해당 값이 t시점의 output(prediction)이 된다.
reference
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
WaveNet: A Generative Model for Raw Audio
This post presents WaveNet, a deep generative model of raw audio waveforms. We show that WaveNets are able to generate speech which mimics any human voice and which sounds more natural than the best existing Text-to-Speech systems, reducing the gap with hu
deepmind.com



