original paper: https://arxiv.org/pdf/2106.07631.pdf
Abstract
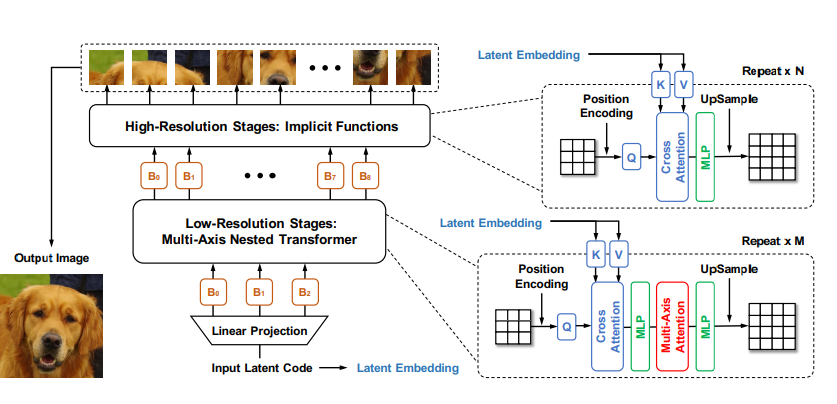
transformer는 long range dependency를 잘 모델링한다. 하지만, 연산 복잡도 때문에 고해상도 이미지 생성에 적용하기 어렵다. 다음 두 개의 핵심 알고리즘을 바탕으로한 계층적 트랜스포머 구조로 이를 해결한다.
1. low-resolution stages: multi-axis blocked self-attention: local, global attention을 효율적으로 섞는다
2. high-resolution stages: MLP + additional self modulation component
트랜스포머 구조로 이미지 생성을 하는 모델 제안, 이미지 크기에 linear complexity, SOTA, convolution 없는 GAN을 위한 중요한 역할을 할 것.
Introduction
트랜스포머로 long term 시퀀스를 모델링하기 좋고, 요즘에는 vision도 잘한다, 근데 GAN에 적용은 어렵다. 이는 다음과 같은 이유 때문이다.
1. high-resolution images일 때 pixel level에서의 self attention은 computational cost가 크다
2. noise를 인풋으로 하는 GAN은 higher demand for spatial coherency in structure
HiT 제안, 트랜스포머를 계층적 구조로 쌓아 생성 과정을 low-resolution and high-resolution stages로 나눈다. low dim은 Nested Transformer 구성에 multi-axis blocked self-attention을 더해 글로벌 정보를 더 잘 포착하게 했다. low dim에서 spatial feature를 잘 포착했다고 가정하고 high dim에서는 MLP 사용하여 연산 복잡도를 줄였다.
+ 추가적으로 성능 향상을 위해 additional cross-attention module 적용
Contributions
1. HiT는 high dim에서 MLP 써서 고해상도 이미지 생성이 용이하게 함
2. multi-axis blocked self-attention: self attention의 capability는 유지하면서 complexity를 줄이는 self-attetion 방법 제안
3. cross-attention module
4. can serve as a general decoder for other models such as VQ-VAE
Approach
Multi-Axis Blocked Self-Attention
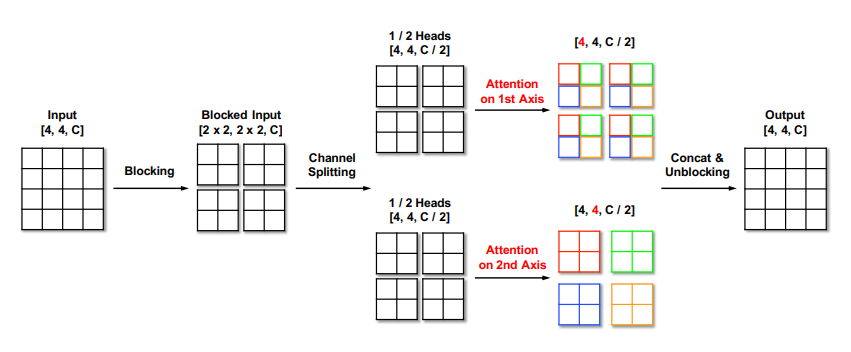
low dim에서 적용되는 연산, 아래 두 가지 self-attention을 병렬적으로 수행하여 연산 효율성 및 local, global feature를 반영한다. 입력 패치를 다시 block으로 나눠서 각 block 간의 global feature를 캡쳐하는 dilated self-attention, block 내에서 local feature를 캡쳐하는 regional self-attention으로 구성된다. 이는 각각 축 방향으로 attention을 적용하는 것이므로, multi-axis self attention으로 일반화 할 수 있다.
dilated self-attention: 위 그림에서 axis 1로 self-attention 하는 부분, global feature를 반영
regional self-attention: 위 그림에서 axis 2로 self-attention 하는 부분, local feature를 반영
위 두 연산을 single layer에서 병렬적으로 컴퓨팅할 수 있다. blocking이 이미지에 대한 좋은 inductive bias(spatial info)로 역할을 한다. 저자는 convolution free image GAN 모델을 제안한건데, blocking을 통해 conv가 image에서 갖는 좋은 inductive bias를 반영할 수 있음을 강조한다.
Cross-Attention for Self-Modulation
high dim, low dim 모두 적용되는 연산, 입력인 노이즈 벡터를 각 transformer layer에 key, value로 linear projection하고, 패치를 query로 해서 multi-head attention을 진행한다. 두 가지 장점이 있는데, 우선 노이즈로 부터 up sampling 하며 이미지를 만들어 내는 계층적 모델인 만큼 각 단계에서 입력 노이즈가 어떻게 반영되는지 연관성을 모델링 할 수 있고 이는 이미지 생성을 안정적이게 해준다. 다음은 attention 연산이 없는 high dim 부분에 이를 적용하므로써 global 정보를 반영할 수 있게 해준다(On self modulation for generative adversarial networks(Chen et al, ICLR 2019)).
'Paper' 카테고리의 다른 글
| [논문] AUDIO TRANSFORMERS:TRANSFORMER ARCHITECTURES FOR LARGE SCALE AUDIO UNDERSTANDING (0) | 2021.09.03 |
|---|---|
| [논문] Dense passage retrieval for Open-Domain QA (0) | 2021.06.08 |
| [논문] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.05.27 |
| [논문-WIP] Lambda Network(ICLR, 2021) (0) | 2021.04.29 |
| [논문] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2021.04.28 |



