original paper: https://arxiv.org/pdf/2105.00335.pdf
Abstract
- Transformer만 써서 raw audio signal을 모델링
- CNN pooling, wavelet decomposition에서 영감을 받은 multi-scale decompostion 임배딩 방법으로 성능을 향상 시킴
- 이 모델을 통해 non-linear & non constant bandwidth filter-bank를 학습할 수 있음
Data
200개의 클래스로 라벨이 붙어 있는 FSD50K 데이터 셋 사용, 51197개 오디오 클립을 1초 단위로 파싱하여 학습에 활용
Methodology
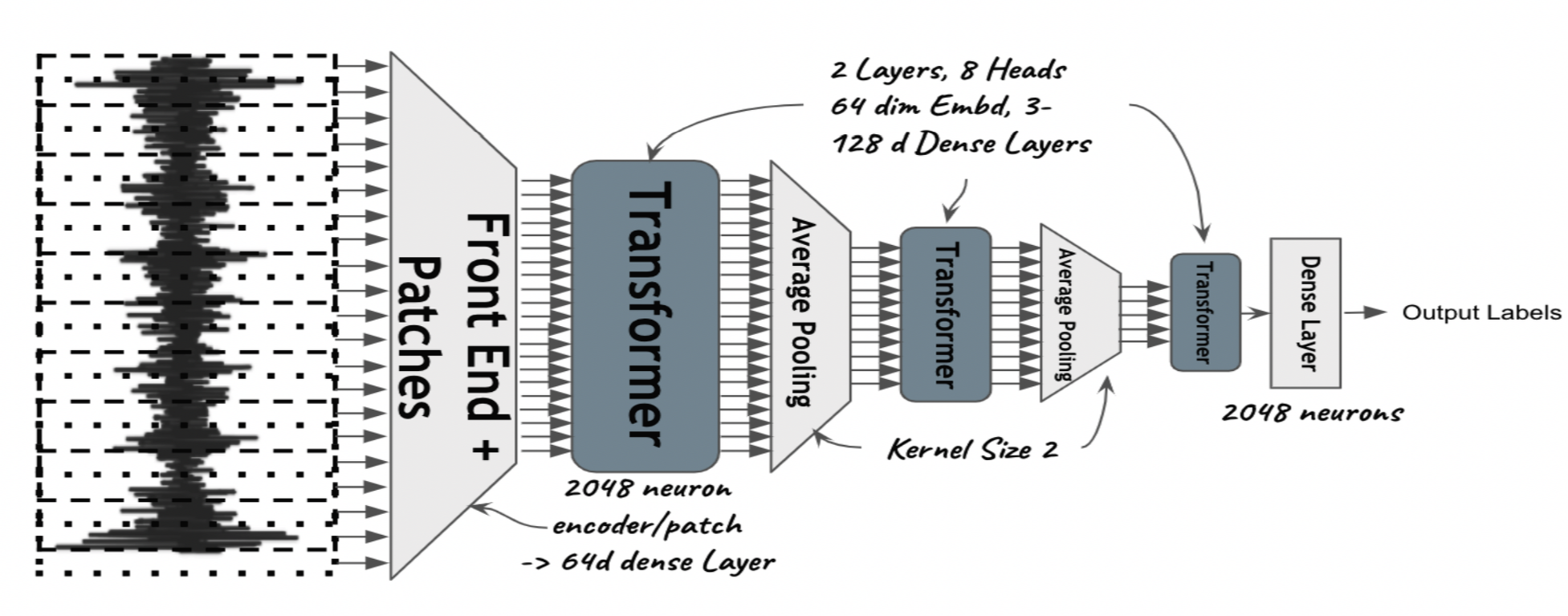
Adapting Transformer Architecture for raw waveforms
sampling rate 16k 오디오 1초를 모델에 입력으로 준다(한 샘플에 데이터 포인트 16000개). 입력을 25ms씩 겹치지 않는 윈도우로 나눠 40개의 patches를 만든다. 이를 2048 차원의 fc layer로 인코딩 한 뒤 64 차원으로 임배딩 하여 transformer 입력으로 사용한다. 이 때, 이 fc layer는 오디오에 대한 filter bank를 학습한다. 3개의 transformer layer를 통과 한 뒤, 마지막에 오디오를 200개 클래스로 분류하기 위한 fc layer를 통과한다.
Transformer Architectures Inspired From CNNs: Pooling
CNN에서 좋은 성능을 보였던 pooling을 모델 구조에 적용했고, 다음과 같은 장점이 있다.
- 입력 크기를 줄여 cost 효율성 증대
- 넓은 receptive field를 가져, hierarchical feature를 학습하는데 유리
실험 결과, pooled transformer는 같은 파라미터 수의 base 모델에 비해 좋은 성능을 보였으며, max pooling 보다는 average pooling이 더 좋았다.
Learning multi-scale embeddings

트랜스포머 임배딩을 wavelet decompostion과 유사하게 시간 축을 multi-scale로 나누는 실험을 했다. 위 그림을 보면 40 x 64의 임배딩 행렬을 시간 축으로 1, 2, 4, 8.. scale로 나눠준다. average pooling과 비슷한 kernel 연산을 사용하지만, 길이는 변하지 않게 scale 만큼 할당해준다. 이를 통해, 임배딩 공간을 계층적으로 모델링할 수 있게 된다. 마지막 그림을 보면 아래 절반은 multi-scaling을 적용하고 나머지 절반은 원래 임배딩을 유지하는데, 이 조합이 wavelet transforms의 핵심이다.
RESULTS & DISCUSSION
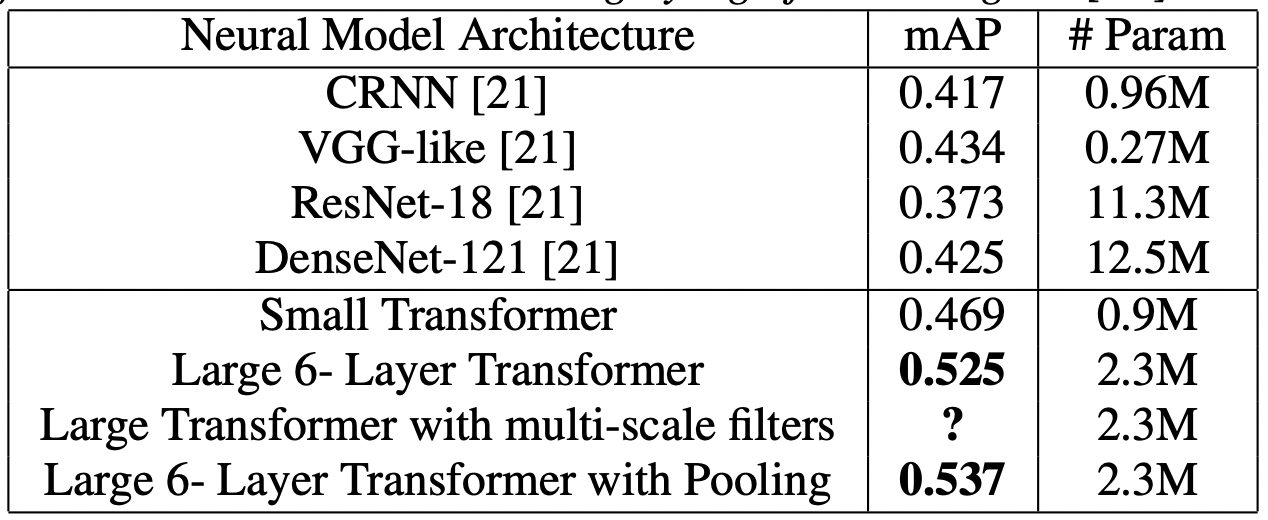
작은 트랜스포머 모델로도 CNN 보다 뛰어난 성능을 보였다. 모델을 깊게 쌓을수록 mAP 성능을 끌어 올릴 수 있었고, 앞서 살펴 본 pooled transformer를 적용하면 성능이 향상됨을 알 수 있었다. multi-scale filter는 아이디어만 제시하고 실험을 안 한 것인지 결과가 나와 있지 않다.
'Paper' 카테고리의 다른 글
| [논문] Improved Transformer for High-Resolution GANs(Zhao et al.) (0) | 2021.10.21 |
|---|---|
| [논문] Dense passage retrieval for Open-Domain QA (0) | 2021.06.08 |
| [논문] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.05.27 |
| [논문-WIP] Lambda Network(ICLR, 2021) (0) | 2021.04.29 |
| [논문] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2021.04.28 |



