Abstract
이때까지의 딥러닝을 활용한 추천 시스템은 RNN 계열을 활용해 unidirectional 하게 유저 상호작용을 히든 벡터로 인코딩했다. unidirectional 모델링은 다음과 같은 문제점이 있다.
- 표현력 한계
- 순서가 무의미 한 경우도 순서를 세우는 문제
이 논문에서는 이러한 문제를 해결하기 위해 bidirectional self-attention을 활용한 Bert4Rec을 제안한다.
Bert4Rec
1. problem statement
- 유저 벡터
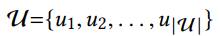
- 아이템 벡터

- interaction sequence: 특정 유저 u가 t 시점에 상호작용하는 아이템 시퀀스

$n_u$ 시점 이전까지의 sequence를 통해 $n_{u + 1}$ 시점의 유저가 어떤 아이템과 상호작용할지 예측하는 문제. 이는 language model과 유사하므로 bert를 사용한다.
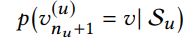
*무엇을 상호작용으로 잡을지는 도메인과 task에 따라 달라진다(ex. 클릭, 구매, 등).
2. Model Architecture
Bert4Rec 모델 구조 설명에 앞서, transformer, bert, gpt 개념을 간단하게 정리해보자. 우선 트랜스포머는 아래와 같이 인코더-디코더 구조를 갖는 seqence-to-sequence 모델이다. 기존 seq2seq 모델과 다르게 self-attention, positional encoding layer를 사용했다.

self-attention은 그 연산 자체가 시퀀스 전체를 여러 방향으로 모델링하므로, bidirectional 하다고 할 수 있다. 따라서 기본 self-attention을 사용하는 트랜스포머 인코더는 bidirectional 하다.
반면 디코더는 masked-self-attention을 사용하고 있는데, 이는 디코더가 auto-regressive 하게 결과를 출력하므로(t 시점 인풋의 정답은 t+1 시점 인풋이 되므로) 각 입력의 t+1 시점 값을 masking 하는 것이다. 즉, "나는 버거킹 가서 햄버거 먹었어"라는 문장에서 "버거킹"을 예측할 때 "나는"만 참고할 수 있으므로 "버거킹 가서 햄버거 먹었어"를 마스킹 처리한다. 따라서 트랜스포머 디코더는 unidirectional 하다.
Bert는 트랜스포머의 인코더 부분만 사용하는 masked language model이다. 이때 masked는 입력 시퀀스에 빈칸(masking)을 만들어 이를 예측하는 방법으로 학습한다는 의미다(디코더에 쓰인 masked-attention과 다르다). 트랜스포머의 인코더만 사용하므로 bidirectional 모델이다.

GPT는 트랜스포머의 디코더만 사용하는 language model(auto-regressive)이고, unidirectional 하다.

다시 논문으로 돌아와서, RNN은 단방향의 영향만 포착하는 것에 반해 트랜스포머는 서로 떨어진 토큰의 상호작용도 포착한다(self-attention) -> global receptive field. 그중에서도 Bert는 SAS, RNN에 비해 bidirection이라 표현력이 더 좋다.
3. Transformer layer
Multi-Head Self-Attention

sequence 간 떨어져 있는 거리에 상관없이 pair representation 학습하는데 용이하다. 서로 다른 space(multi-head)에 projection 시켜서 병렬적으로 포워딩하여 연산 효율성 및 각기 다른 space에서 다른 feature 추출 기대. 이후 concat 해서 다시 하나의 space에 projection 한다.

이후 attetion 연산을 거쳐 Position-wise Feed-Forward Network로 포워딩한다.
Position-wise Feed-Forward Network
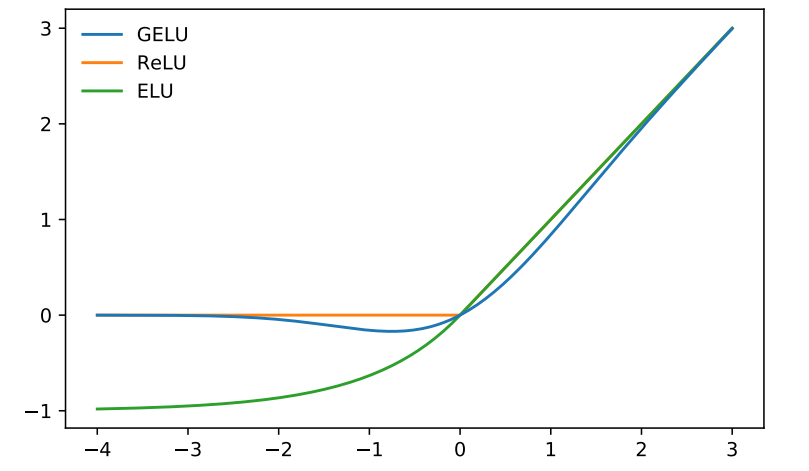
Multi-Head Self-Attention은 linear projection이라 비선형성을 줘야 한다.
FC layer + GELU로 비선형성을 줬다.
4. Embedding layer
트랜스포머는 위치정보를 소실하기에 positional embedding layer를 추가해준다. Bert4Rec은 positional embedding으로 fixed sinusoid embed 대신 학습 가능한 임배딩 레이어를 사용한다. 대신 인풋 임배딩 레이어를 고정된 Look Up Table로 사용한다. 보통은 positional 임배딩을 sinusoid로 고정값으로 주고 인풋 임배딩을 learnable 하게 하는데, 이 논문은 반대로 positional 임배딩을 학습하고 인풋 임배딩을 고정된 LUT로 본다.
마지막에 softmax로 어떤 아이템과 상호작용할지 확률을 계산하는데 이는 item_size에 연산량 디펜던시를 갖는다.
5. Model Learning
Cloze task(빈칸 채우기)로 학습한다. 인풋 시퀀스를 중간중간 랜덤 하게 마스킹하고 해당 라벨을 맞추게 학습한다.

라벨과 예측값 간의 loss를 다음과 같이 negative log likelihood로 정의한다.

Cloze task의 또 하나의 장점은 하나의 sequence에서 여러 학습 샘플을 뽑을 수 있다.
Inference 시에는 추천 시스템이므로 t+1 시점, 즉 마지막 토큰만 마스킹해서 inference 한다. 근데 이렇게 inference 할 거면 학습 시 마지막 토큰만 마스킹한 시퀀스만 사용하는 것도 좋아 보인다.
6. Discussion
기존 Bert와 차이점
- Bert는 NLP를 위한 pre-trained 모델이라 end-to-end 모델이 아닌 반면, Bert4Rec은 도메인 별 데이터셋이 상이하므로 end-to-end 모델
- Bert4Rec은 유저의 sequence를 하나로 보기 때문에 next sentence loss와 segment embedding 사용 안 함
'Paper' 카테고리의 다른 글
| [논문] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2021.04.28 |
|---|---|
| [논문-WIP] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction (0) | 2021.04.15 |
| [논문] GPT-2 (0) | 2021.03.04 |
| [논문] Session-based recommendations with RNN (0) | 2020.12.12 |
| [논문] Graph Convolution Matrix Completion(GNN) (2) | 2020.11.05 |



