Overview
GPT-2는 트랜스포머의 디코더만 사용하는 langauge model 이다. 인코더를 사용하는 BERT와 다르게 auto-regressive하다. 즉, 시작 token '<s>' 로 token 'The' 를 추정하고 추정된 'The' 를 다시 인풋으로 다음 token을 추정한다.
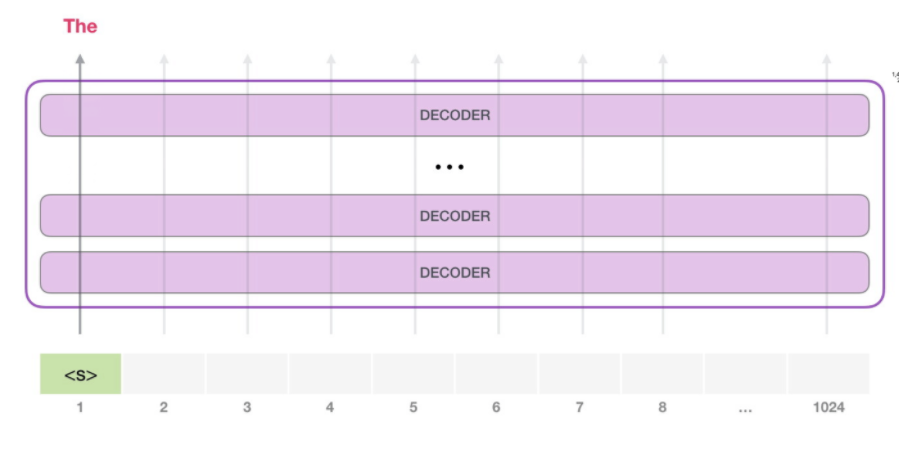
각 디코더는 masked self-attention과 FC로 구성, 기존 트랜스포머에 있는 encoder-decoder self-attention은 인코더가 없기에 사용하지 않는다.

Input embedding
인풋 token 임배딩은 byte pair encoding을 사용, GPT 모델 크기에 따라 임배딩 차원이 정해진다.

Masked Self-Attention
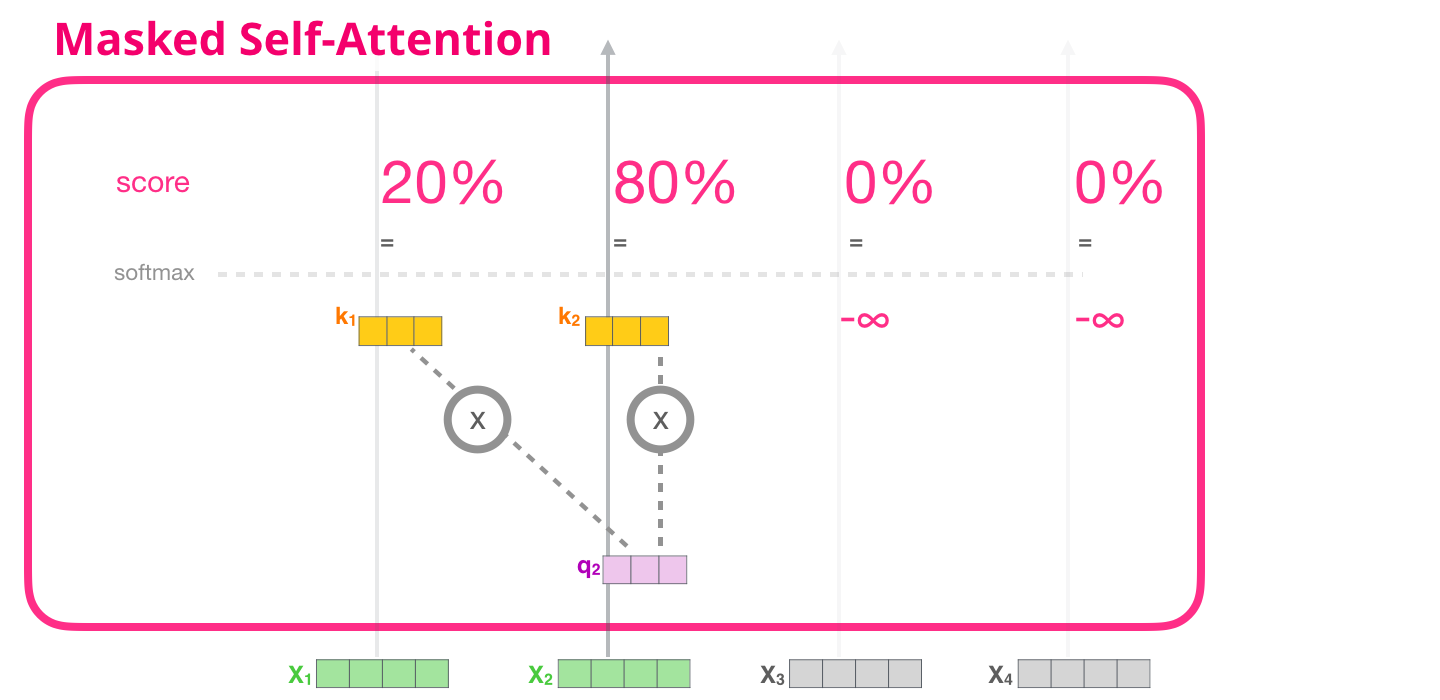
Masked self attention은 현재 query 시점 이전의 값들만 attention score 계산할 때 사용한다. 기존의 self-attention은 다음과 같이 attention matrix를 구한다.
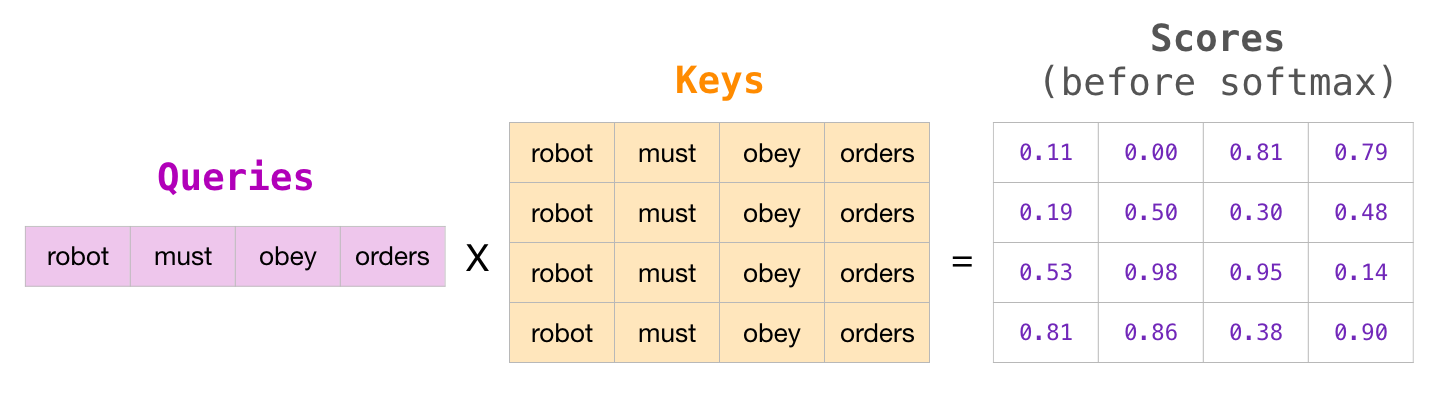
여기에 mask를 적용하면 다음과 같이 triangular matrix 형태로 우상단을 masking 한다. 아직 softmax 취하기 전이니, 매우 작은 음수값(-inf)을 줘서 softmax 값이 0에 수렴하게 한다.

layer normalization

GPT-2는 이전 ver. GPT와 다르게 layer normalization을 사용했고 성능향상이 있었다. layer normalization은 각 feature들의 평균, 분산으로 각 feature를 정규화하는 BN과 달리 샘플 단위로 평균과 분산을 구해서 샘플을 정규화한다. 따라서 BN은 batch size와 상관있지만, LN은 상관없다. BN은 딥러닝 학습 과정에서 layer를 거칠때마다 각 차원(feature)의 scale이 불균형해지는 것을 막아 안정적인 학습을 가능하게 한다. 한편, LN은 샘플 단위로 정규화하므로 output 값 자체를 줄이는, 즉 gradient를 줄이는 효과를 갖고 이를 통해 안정적인 학습을 도와준다.
트랜스포머는 학습 초기 output 단의 gradient가 크게 발생하므로 gradient cliping, warm-up training(매우 작은 LR로 초기에 학습), layer normalization을 적용하는게 좋다. On layer normaliztion in the transformer architecture [Paper] 논문을 보면, layer normalization 위치를 조정해 warm-up training 없이도 보다 안정적인 학습이 가능하다. GPT-2는 기존의 layer nomalization을 사용했다(GPT-2, 2019/ On layer norm ~, 2020).
'Paper' 카테고리의 다른 글
| [논문-WIP] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction (0) | 2021.04.15 |
|---|---|
| [논문] BERT4Rec: Sequential Recommendation with BidirectionalEncoder Representations from Transformer (0) | 2021.04.08 |
| [논문] Session-based recommendations with RNN (0) | 2020.12.12 |
| [논문] Graph Convolution Matrix Completion(GNN) (2) | 2020.11.05 |
| [논문] Deep Face Recognition + Arcface (2) | 2020.09.07 |



