[음성인식] Lec.4_1 Acousitc Model (HMM-GMM)에서 살펴본 acousitc model은 HMM-GMM 기반 모델입니다. 그 중 HMM에 대해서 공부한 것을 정리했습니다.
HMM을 이용해 특정 word를 pronunciation에 해당하는 phone들의 sequence로 나타낼 수 있다. 이를 통해 라벨링 되어있지 않은 speech data로 speech tagging이라는 supervised learning이 가능하게 된다. HMM 전에 근간이 되는 Markov chain부터 알아보자.
Markov Chains
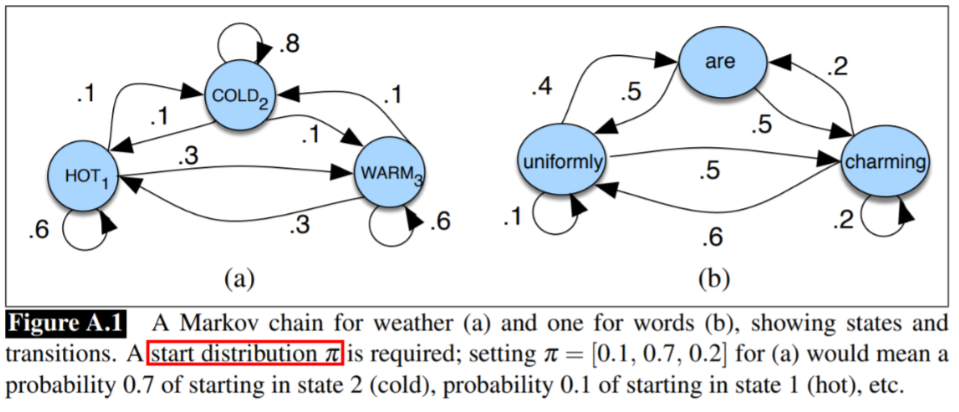
연속적인(sequential) 랜덤 변수의 확률에 대한 논의. 위 그림에서 파란색 동그라미가 state, 화살표는 transition probability(전이 확률 ; 다음 state로 갈 확률)를 나타낸다. Markov chain의 핵심 가정은 t+1 시점의 state가 오직 현재 t 시점의 state에 의해 결정된다는 것이다. q를 state라고 할 때 수식으로 나타내면 다음과 같다.
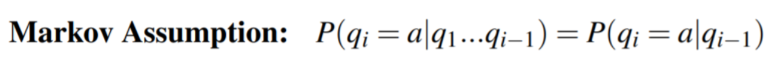
Markov chain을 구성하는 요소는 다음과 같다.

정리하자면, Markov chain은 연속적인 이벤트들의 확률 계산에 용이하다. 그러나 세상에는 관측되지 않는 값들이 있다. 예를 들어 내일의 주가를 예측한다고 했을 때 우리에게 주어진 데이터가 재무제표, 매출액 등이라고 하면 우리는 알고자 하는 state인 주가에 대한 정보가 없다. 이를 모델링하기 위해 알고자 하는 상태를 hidden state로 정의하는 Hidden Markov Model(HMM)을 사용한다.
Hidden Markov Model
HMM의 구성요소는 다음과 같다.

Markov Model과 비교했을 때, 관측값 O(Observation)와 관측값에 대한 가능도인 방출 확률(emission prob) B가 추가되었다. HMM의 목표는 우리가 관측 가능한 값 O가 주어지면 hidden state Q를 맞추는 것이다.
예를 들어보자. 날씨(hidden state)가 궁금한데 우리에게 주어진 값은 먹은 아이스크림 개수(Observation) 뿐이다.

위 그림에서 HOT, COLD가 우리가 궁금한 날씨(hidden state), 1,2,3 이 각각 먹은 아이스크림 개수(Observation)가 된다. 여기서 우리는 날씨(hidden state)가 주어졌을 때 먹은 아이스크림 개수에 대한 방출 확률 B를 정의할 수 있다. 이는 각 hidden state에 대한 관측값의 가능도(observation likelihood)가 되고, hidden state로부터 관측값이 튀어나올 확률이므로 방출 확률(emission probability)이라는 이름이 붙었다. 밑에 있는 파이는 initial 확률 분포로 state의 초기 상태를 결정해준다. 여기서는 {.8 , .2} 이므로 각각 날씨가 더울 확률이 0.8, 추울 확률이 0.2인 상태로 시작한다는 의미이다. Markov chain은 우리가 알고자 하는 현상(날씨)의 확률을 바로 알 수 있지만 HMM은 우리가 알고자 하는 현상(날씨)을 알 수 없고, 관측 가능한 현상(아이스크림)이 따로 존재하는 경우이다. 따라서 날씨가 hidden state가 된다.
HMM의 과정은 다음과 같다.

1. HMM의 파라미터 A(transition prob), B(emission prob)가 주어졌을 때, 관측값 O의 likelihood를 계산, 즉 P(O | A, B)를 계산. 지금까지 정한 파라미터(A, B)로 관찰된 상태(O)들을 계산해 놓는다는 의미이다. 관측 sequence O는 이미 정해진 값이고 파라미터 A, B가 변수인 함수이다.
2. A, B, O가 주어졌을 때, best hidde state(Q)를 결정.
3. O와 Q가 주어졌을 때, 1에서 사용할 HMM 파라미터 A, B를 학습(추정)하고 업데이트.
HMM은 위 세 가지 과정을 반복하며 작동한다. 각 과정 계산에 적용되는 알고리즘에 대해 알아보자.
Likelihood(prob.1)
이 과정의 예를 들어보자. 이미 모델(A, B)이 위 그림과 같이 주어졌다고 할 때, 3일 동안 먹은 아이스크림 수(O)가 [3, 1, 3]으로 관측될 확률을 구하는 것이 likelihood 계산 과정이다. 수식으로 나타내면 다음과 같다.
P(3 1 3 | A, B)

위 그림은 3일간 날씨가 hot, hot, cold 였을 때 likelihood를 구하는 과정이다. 수식으로 나타내면 다음과 같다.
P(3 1 3, hot hot cold) = P(hot|start) x P(3|hot) x P(hot|hot) x P(1|hot) x P(cold|hot) x P(3|cold)
하지만 우리는 3일간의 날씨가 어떨지 모르기 때문에 모든 가능한 경우에 대해 위 연산을 해서 더해줘야 최종적인 먹은 아이스크림 수(O)가 [3, 1, 3]으로 관측될 likelihood를 계산한 게 된다. 각 경우에 대해 표로 나타내면 다음과 같다.

위와 같은 방법은 상당히 나이브하고 계산 복잡도가 높다. 따라서 dynamic programming 중 하나인 forward algorithm을 사용해 likelihood를 계산한다.
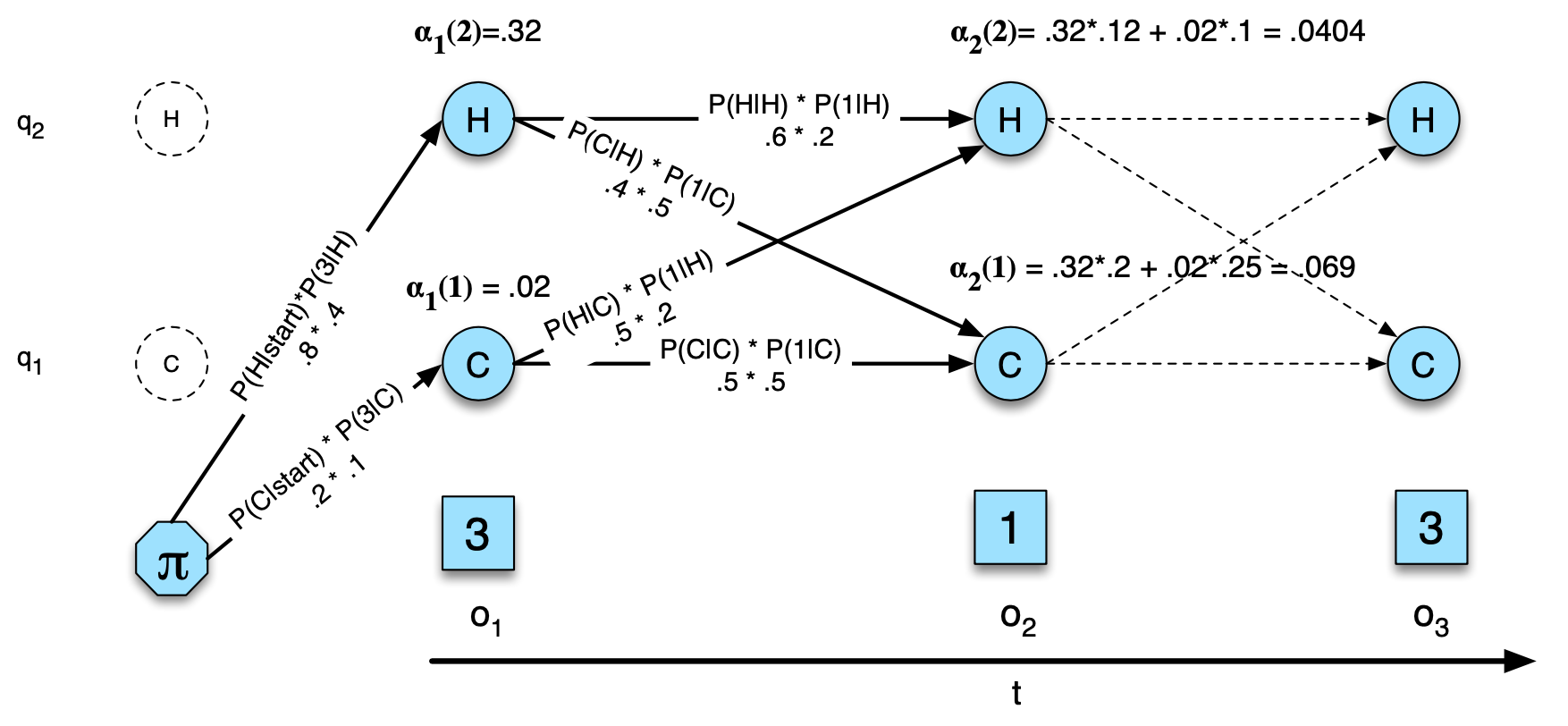
포워드 알고리즘은 중복되는 계산 결과를 저장해 두었다가 필요할 때 불러 쓰자는 아이디어다. 각 state에서 정의되는 forward probability(전방 확률)는 t 시점까지 관측값들 O1, O2,.., Ot가 관측되었을 때 t 시점에서 j state로 올 확률을 의미한다.
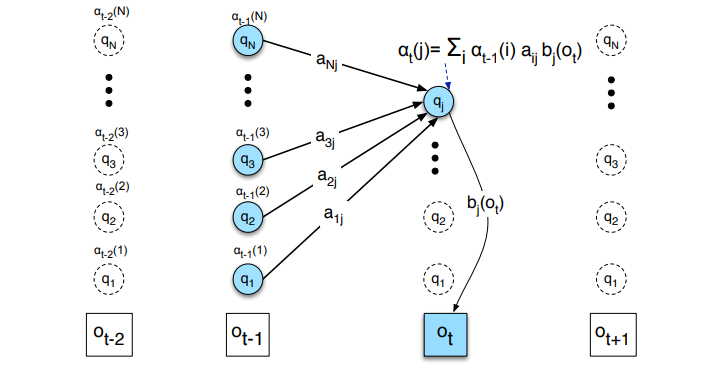
위 그림과 같이 해당 state로 올 수 있는 모든 path에 대해 확률을 더해서 계산하며 다음과 같이 정의한다.
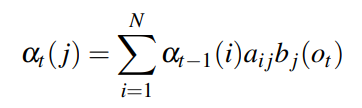
각 argument는 다음과 같은 의미를 가진다.

즉, forward 값은 전이 확률과 방출 확률의 누적 곱으로 계산되고 이를 통해 계산 복잡도를 줄일 수 있다.
Decoding(prob.2)
디코딩은 모델과 관측 시퀀스 O가 주어졌을 때 hidden state Q의 best path를 찾는 과정이다. 음성인식에서는 각 hidden state에 phones이 들어가 있으므로, 관측값인 특정 음성 신호(O ; MFCC)를 가지고 best phones sequence를 찾는 과정을 의미한다. 이 과정에는 비터비 알고리즘(Viterbi Algorithm)이 사용된다.
비터비 알고리즘은 위에서 살펴본 포워드 알고리즘과 매우 유사하다. t 시점에 j state의 viterbi probability는 다음과 같다.
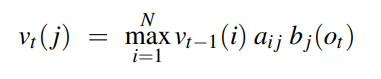
수식을 보면 포워드와 동일하게 각 상태에서의 전이 확률과 방출 확률의 곱을 계산한다. 포워드는 이를 모든 path에 대해 sum 했다면, 비터비는 max를 취해 해당 state로 오는 path 중 가장 높은 확률 하나만을 그 값으로 가진다.

비터비 알고리즘의 핵심은 viterbi backtrace이다. 디코딩에서는 최적의 hidden state를 구성하는 path를 찾는 게 목표다. 위 그림에서 역방향 점선 화살표가 그 역할을 하는 viterbi backtracking이다. t 시점, j state의 viterbi backtrace는 t-1 시점의 viterbi probability이 큰 state를 출력한다. 그 결과값을 나타낸 게 점선 역방향 화살표이고 다음과 같이 정의한다.

앞서 구한 비터비 확률과 backtrace를 이용해 우리는 best hidden state sequece를 디코딩할 수 있게 된다!
* 마지막 과정인 learning에 사용되는 E-M 알고리즘 중 하나인 Baum–Welch algorithm에 대해서는 [음성인식] 4.3 Baum–Welch algorithm에 이어서 다루겠습니다.
'Audio & Speech' 카테고리의 다른 글
| 오디오 데이터 전처리 (1) Waveform (7) | 2020.04.02 |
|---|---|
| [음성인식] 4.3 Baum–Welch algorithm (1) | 2020.04.02 |
| 오디오 데이터 전처리 (5) MFCC (7) | 2020.03.25 |
| 오디오 데이터 전처리 (2) Fourier Transform & Spectrogram (2) | 2020.03.25 |
| 오디오 데이터 전처리 (4) Mel Filter Bank (2) | 2020.03.25 |



