모두의 연구소에서 진행되는 음성인식 부트캠프 풀잎스쿨에서 공부한 내용을 토대로 정리하였습니다.
음성인식?
- 공기의 진동인 파형(음성) -> 텍스트 (STT)
근데 컴퓨터는 숫자만 인식하니까
- 음성 파일의 sequential 벡터(소리의 압축/수축 정도 값(음압)을 가지게 됨) -> 텍스트로 sequential 벡터로!
- sequence input > sequence output (인풋 아웃풋의 길이가 가변적이라는게 challangeble한 task)
음성과 단어는 일대일 관계가 아니다 → 단어를 좀 더 추상화된 표현으로 바꾸자
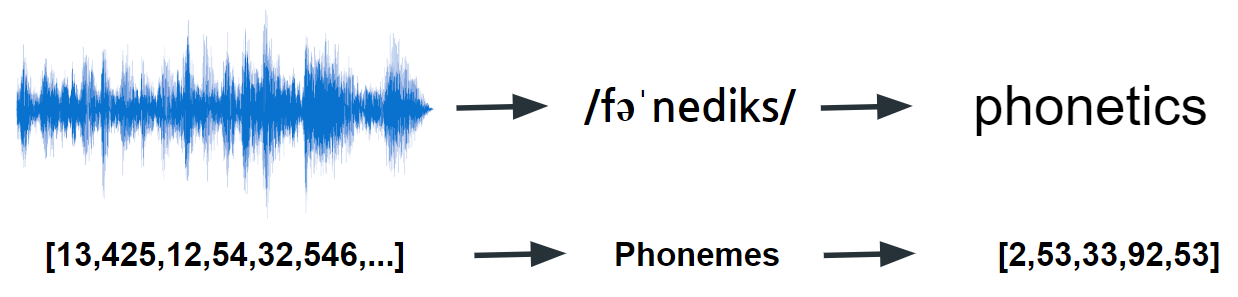
- 음성에서 바로 단어로 가지말고, 음성에서 Phonemes(발음)으로 가고 그 다음에 단어로 가자!
Acoustic features
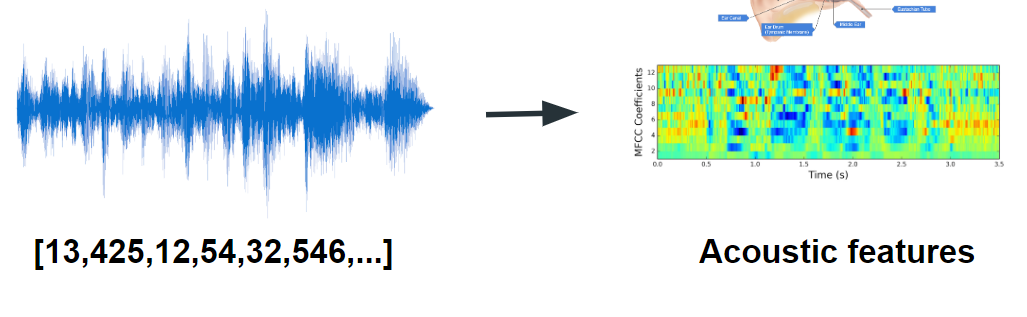
- 발성기관과 듣는기관은 같이 발달되었다. 따라서 귀를 본따서 특정 주파수에 맞는 features를 모델링(Acoustic features)을 하면 효과적이다. 즉 사람이 잘 듣는 부분은 웨이트를 주고 아닌 부분은 버리는 방법
- X축은 시간으로 동일하지만 Y축이 음압에서 주파수로 바뀐다
Bayes 정리
- P(Text|Sound) ~ P(Sound|Text)=AM(acoustic model) * P(T)=LM(language model)
- 이렇게 베이즈 정리관점에서 보면 , 음성 task는 AM과 LM으로 나눌 수 있다.
Hidden Markov Chain & Gaussian Mixure Model(GMM-HMM)
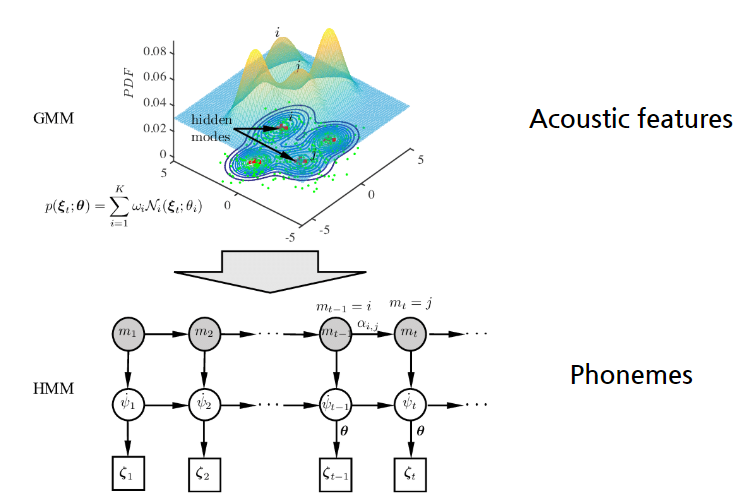
- 음향 모델에서 자주 쓰이는 GMM-HMM 모델, Accoustic feature를 보고 phonemes라는 숨어있는 변수를 맞추고자 한다.
Neural Network Acoustic Models

- 인공신경망을 사용한 음향 모델, Hybrid model이라고도 부른다.
End-to-End Neural Network Recognition

- AM, LM을 나누지 말고 처음부터 끝까지 하나의 모델로 해결해보자
- CTC, Seq2Seq, RNN Transducer 등의 모델이 있다.

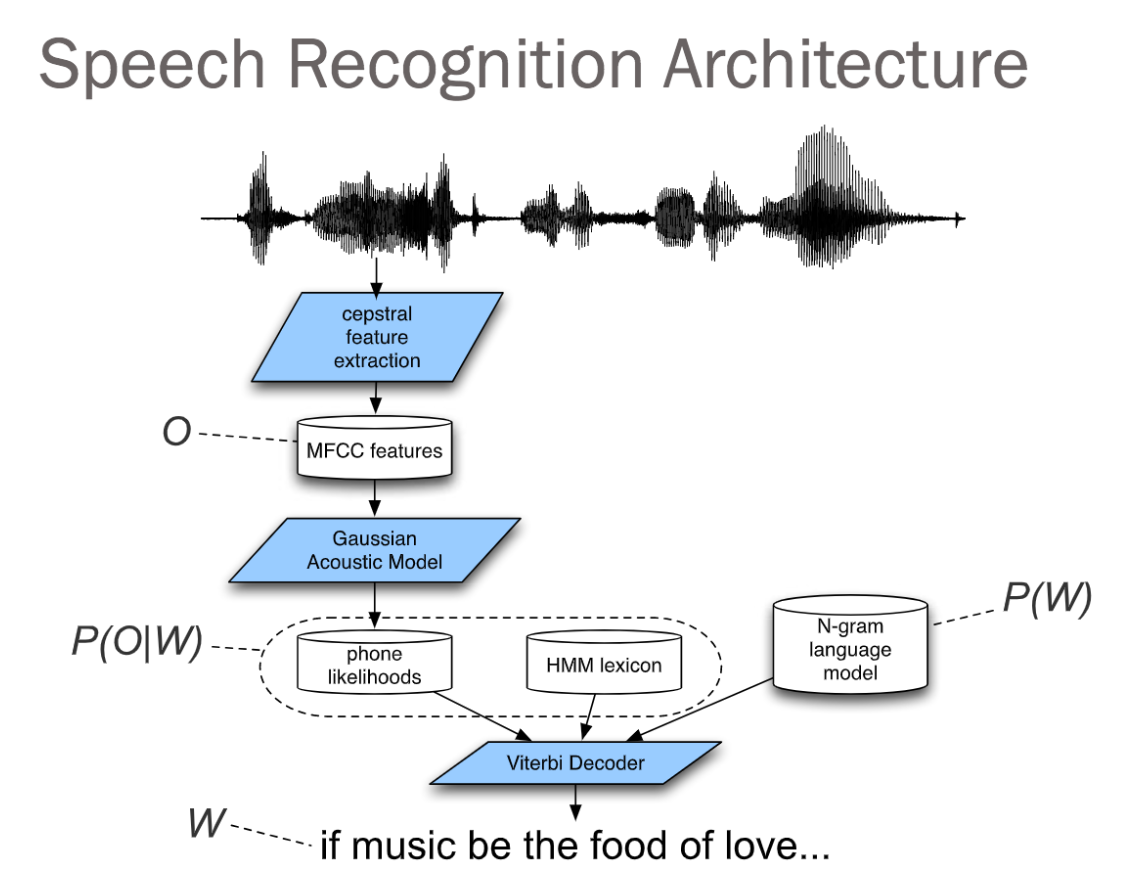
음성인식 알고리즘은, 음성 data에 대한 모델인 AM(Accoustic Model)과 text data에 대한 모델인 LM(Language Model) 로 구성된다.
① wave form의 음성 data를 MFCC feature vector로 feature extraction 하는 과정과
② transcription > Lexicon > HMM(LSTM이나 어텐션을 사용해도 되지만! cost 문제로 안 쓴다, HMM이 빠르다)
AM은 위 두 과정을 독립적으로 진행하다, 음성에 대한 feature vector와 텍스트에 대한 Lexicon을 mapping한다. 원래는 GMM을 이용해서 mapping하는데, 이게 최근에 GMM 대신 Neural Net 모델을 쓰면서 성능이 많이 올라갔다.이후 LM 하고 Viterbi Decoding을 해, 최종 텍스트를 출력한다.
'Audio & Speech' 카테고리의 다른 글
| 음성 데이터의 활용 (0) | 2020.02.17 |
|---|---|
| [음성인식] 5.1 Vector Quantization(VQ) (0) | 2020.02.15 |
| [음성인식] 4.1 Acousitc Model (HMM-GMM) (0) | 2020.02.08 |
| [음성인식] Lec.3 Acoustic feature extraction (0) | 2020.02.01 |
| [음성인식] Lec.2 Phonetics & Signal process 기본 개념 (0) | 2020.01.17 |



