word embedding
기존 w2v, Glove와 같은 단어 수준 임배딩은 단어를 하나의 vector representation으로 나타내므로 한계가 있다. LSTM 등 language model은 각 hidden에서 context-specific word representation을 갖는다. 이러한 LM의 context-specific word representation 자체를 임배딩 벡터로 이용해볼 수 있지 않을까? Language Model 을 활용한 단어 임배딩을 알아보자.
Language model word embedding
앞서 언급했듯이 LSTM 등 language model은 문맥 정보를 반영한 context-specific word representation를 갖는다. 이를 단어의 임배딩 벡터로 활용하면 문장 수준 단어 임배딩이 가능해진다. 이를 활용한 첫 예시가 아래에 있는 Tag LM이다.

Tag LM은 인풋 sequence를 두 개의 네트워크로 각각 임배딩하고 concat 하여 최종 임베딩 벡터를 만들고, 이를 task에 따른 모델에 넣는 구조를 가진다. 왼쪽은 char-CNN을 활용한 token 임베딩(문맥 정보가 반영되지 않는다), 오른쪽은 bi-rnn LM을 활용한 임 배딩(문맥 정보가 반영되어 context-specific word representation을 얻는다). 이렇게 LM 모델로 임베딩 하면 기존 단어 수준 임베딩(w2v)의 정보 한계를 극복할 수 있을 뿐만 아니라 대량의 데이터로 task에 맞게 pre-trained 된 LM을 활용할 수 있는 장점이 있다. 이러한 pre-trained LM은 일반적으로 weight를 고정한다. ELMo, Bert, GPT-2로 가면 갈수록 pre-trained data 크기가 커졌기 때문에 애매한 데이터로 fine tunning 하는 것보다 LM weight를 고정해서 사용하는 게 cost/성능 모든 면에서 일반적으로 좋다.
ELMo
ELMo는 Tag LM을 개선한 모델이다. 2-layer biLSTM 모델을 사용하고, char-CNN으로 input 단어 벡터를 구한다. 아래 그림에서 파란색 벡터가 char-CNN으로 구해진 임배딩 벡터다.

이후, forward, backword LM 각 level의 hidden vector를 concat하고 weighted sum 한다.

이때 weights $s$는 학습되는 파라미터다. 각 level 임배딩마다 갖는 정보가 다르니 task에 맞게 최적의 level 임베딩 별 조합을 찾는 과정으로 보인다.
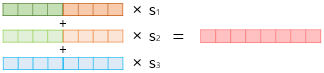
마지막으로 task specific하게 감마만큼 scaling 해주면 ELMo 임베딩 벡터가 나온다.

Tag LM과 동일하게 이를 GloVe와 같은 임베딩 벡터와 concat하여 task에 최종 인풋 임베딩 벡터로 사용한다.
수식으로 보면 다음과 같다.
$x$는 인풋, $h$는 biLSTM hidden vector, $s$는 layer level 별 weights, $\gamma$는 task specific weights


'ML & DL' 카테고리의 다른 글
| Hugging Face 기초 😇 (2) | 2021.04.23 |
|---|---|
| [DL] Pytorch Lightning ⚡ (9) | 2021.04.08 |
| [NLP] Language Model, Seq2Seq, Attention (0) | 2021.02.10 |
| [Deep learning] 4장 수치 계산(Numerical Computation) (0) | 2021.01.18 |
| [Deep learning] 8장 최적화 ① (1) | 2021.01.14 |



