※ 논문 읽는 Tips
Abstract는 왜 이러한 연구를 했고, 내가 얼마나 잘했는지 얘기하는 것
이후 선행 연구를 언급하며 자신의 연구 진행 과정을 설명한다.
▶ Object Detection 이란?
Classification과 Localization을 multiple objects에 대해서 시행하는 것. Classification은 전체 영상에서 특정 객체의 존재 여부만 알아내면 되지만, detection은 위치까지 파악을 해야 하고, 해당 개체 주위로 bounding box를 쳐서 구분을 해줘야 하기 깨문에 Classification에 비해 복잡하고 CNN으로 구현 할 때도 이점을 고려해줘야 한다.
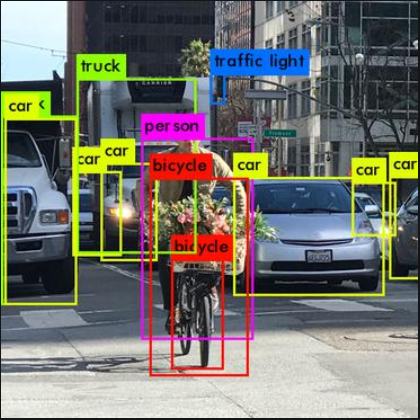
다음과 같은 두 가지 Detection 방식이 있다.
① 2-stage Detector : Input image에 대해서 region proposal을 하고 classification을 하는 방식(모든 R-CNN 계열이 해당한다)
② 1-stage Detector : classfication + localization 동시에 하는 모델 YOLO, SSD 등이 해당한다

cf) CNN은 기본적으로 3차원 데이터인 이미지 데이터를 공간정보를 유지하면서 FC를 쓰기 위한 1차원 데이터로 줄여주는 기법이다
▶ mAP(mean average precision)

Precision(정확도) : true라고 예측한 값 중 실제 true인 비율
Recall(재현율) : 실제로 True인 값들 중에서 내가 True라고 한 값의 비율
둘은 trade-off 관계에 있다. 한 class에 대한 각 recall값 마다의 precision을 평균 낸 값이 AP(average precision)가 된다. 이 AP를 모든 class에 대해서 각각 구하고 총 평균을 낸 값이 mAP가 된다.

R-CNN에서는 IOU가 기준값 이상인 것(0.3)들(positive)만 가지고(SVM에서 1로 mapping) class 별로 ROI의 precision 평균을 낸 것이 AP, 이를 모든 class에 대해 평균을 낸 값이 mAP가 된다.
IOU(intersection over union)

Ground truth, 즉 우리가 true 값이라고 정해진 영역과 우리가 Prediction한 영역의 교집합을 IOU로 정의한다.
이 논문에서 IOU는 크게 두 가지 개념에 쓰이는데 전자는 positive window와 background winndow(negatives)를 나누는 기준 IOU > 0.5 가 있고,
후자는 SVM classify 때 0,1로 object가 있는지 없는지 정답 label mapping에 사용되는 IOU > 0.3 기준이 있다.
이렇게 data에 정답 label(taget)이 있어야 SVM을 통해 loss를 구할 수 있고 superviesd learning의 학습이 가능해진다.
▶ Object detection with R-CNN
r-cnn은 3가지 modules로 구성되어 있다

① Generate category-independent region proposals > seletive search를 통해, region proposal(detection 후보 box 추출)
② Convolutional network를 통해 각 region의 고정된 크기의 feature vectors를 뽑아낸다.
③ Linear SVMs을 활용하여 classify한다. > linear SVM은 0, 1로만 classify 할 수 있다.
각 modules을 자세히 살펴보자!!
Region proposals
- 이때까지의 CNN 연구에서 region proposals을 하기 위한 여러 방법을 사용하였다
- 우리는 선행연구와의 비교를 위해 seletive search 방법을 사용하겠다
Feature Extraction
- 각 region proposal마다 4096-dim의 feature vector를 Caffe implementation CNN 아키텍처를 사용해 뽑아낸다
- 이 아키텍처에 맞는 fixed size(227 X 227 pixel size)로 region proposal을 warpping 해준 뒤 input한다. CNN은 input date의 size가 동일해야되기 때문
▶ Test-time detection
- 테스트 시에 selective search를 통해 2000개 정도의 region proposals를 뽑는다이 region proposals을 wrap해서 CNN에 넣고 feature를 뽑아낸다.
- SVM을 이용해 뽑힌 feature vector를 각 class에 대해 점수를 매긴다
- 이렇게 매겨진 점수에 대해 Greedy non-maximum suppression을 각 class에 독립적으로 적용한다
- Greedy non-maximum suppression은 각 region 별로 IOU 값을 계산해서, IOU > 0.5에 대해 confidence 값을 기준으로, 한 object에 대해 중복되는 bounding box를 제거한다.
- 이를 통해, 연산량도 줄이고 mAP는 올리는 효과를 얻을 수 있다
▶Training
Supervised pre-training & fine-tuning
우선 large dataset(ILSVSR2012, classification)을 가지고 CNN 모델을 pre-trained 시킨다
Pre-trained CNN을 우리의 새로운 task에 적용하기 위해 fine tuning 시킨다
fine tuning은 크게 두 가지 과정으로 나뉜다
① 현재 task의 정답 label 수에 맞춰 마지막 classification layer 수를 조정해준다 - N(class 수)+1(background) > background를 추가해줘야 되는 이유는 negative 값들이 mapping 될 공간이 필요하기 때문이다.
② Wraped region proposals만을 이용해 SGD를 통해 CNN 파라미터들을 훈련시킨다
region proposals data에서 ground-truth box(최대 IOU값을 가지는 proposal)와의
IOU>=0.5 이면 positive(positive window)
IOU<0.5면 negative(background window)로 mapping 시킨다.
이후, 매 SGD iteration마다 모든 class에서 32개의 positive window와 96개의 background window를 뽑아 mini-batch를 만들고 이를 활용해 Pre-trained CNN 모델을 finetuning 시켜준다.
Object category classifiers
Postive Sample : 각 class별 object의 ground-truth bounding box
Negative Sample : 각 class별 object의 ground-truth와의 IOU<0.3인 region
※ IOU>0.3인데 ground truth는 아닌 proposal region은 무시한다.
※ IOU가 CNN fine-tuning 과 object detection SVM 학습시에 positive/negative를 다른 기준으로 구분한다
▶Bounding box regression
최종적으로 학습된 bounding box를 ground-truth로 조금 이동 시켜 최적화 시켜주는 방법

결론적으로, 지금까지 공부한 R-CNN 모델을 정리해보면 다음과 같다.

fast R-cnn
FC는 무조건 input 차원이 동일해야 한다
이를 위해 ROI pooling을 사용한다
fine tuning 할 때 rcnn과 다르게 이미지 2개에 각각 region proposals 2000개 중 64씩 총 128개를 뽑아서 positive/negative로 미니 배치를 만들어 학습을 시킨다. rcnn은 이미지 1개에서 128개를 미니배치로 활용한다.
'Paper' 카테고리의 다른 글
| [논문] TIMBRETRON: A WAVENET(CYCLEGAN(CQT(AUDIO)))PIPELINE FOR MUSICAL TIMBRE TRANSFER(2019) (1) | 2020.03.16 |
|---|---|
| [논문] CAM, Grad-CAM (0) | 2019.12.03 |
| [논문] YOLO (0) | 2019.11.19 |
| [논문]ResNet (0) | 2019.11.14 |
| [논문]Faster R-CNN (0) | 2019.11.12 |
