Music Style Transfer with Neural Network 프로젝트를 진행과정 중 고민들을 적어 둔 글입니다. 해당 프로젝트는 정상형(한양대학교), 이현(건국대학교), 구교정(한양대학교)이 함께 진행했음을 밝힙니다. 2020.02~ 08 마감!
구어체로 러프하게 작성된 점 양해부탁드립니다.
Abstract
음악 스타일을 바꿔주는 네트워크를 만들어보자, eg) IU 좋은날 -> IU 좋은날 Jazz ver.
Paper
다들 해당 주제에 대해 아는 것이 적어서 관련 논문을 공부하는 것부터 시작했다.
크게 task를 3가지로 나누고 각 task에 해당하는 논문을 찾아 읽었다.
1. Style transfer
우리 프로젝트의 핵심 task, 가장 많은 논문을 찾아보았다. 대부분 generative model인 cycleGAN을 이용하는 경우가 많았다. 핵심 아이디어는 음원을 푸리에 변환을 통해 frequency domain으로 넘긴 뒤, CQT(spectrogram)을 활용한 image-to-image CycleGAN이다. 신기했던 점은 음악 데이터를 frequency domain에서 이미지처럼 취급해 cycleGAN을 적용했다는 것, phase 정보를 살리기위해 spectrogram이 아닌 CQT등을 활용했다는 점 등이 였다. 다음의 논문들을 읽고 공부했다.
1) WaveNet
2) GANSynth : Adversarial Neural Audio Synthesis
3) Symbolic muisc genre transfer
4) Timbretron
5) Universial Music translation
근데, frequency domain에서 style transfer를 하면 밑에서 살펴볼 3)reconstruction 문제도 있고 결과물의 resoultion이 보장되지 않을 것 같아서 time domain에서 시도해보자는 생각이 들었다. 5) Universial Music translation 논문을 보면 time domain에서 style transfer를 진행한다. 그래서 이 논문을 기반으로 프로젝트 방향성을 잡았다.
2. Audio Source Separation
맨 처음부터 나왔던 아이디어는 아닌데, 음악의 domain(style)을 변환하려고 하다보니 전체곡을 대상으로 하는 것보다 음악을 구성요소(드럼, 베이스, 보컬, 나머지)로 분리한 뒤 domain transfer하는게 합리적이라고 생각했다. 2018, 2019, 2020년도에 각각 발표된 3개의 논문을 순서대로 공부했다.
1) Wave-U-Net(2018)
2) Demucs Deep Extractor for Music Source separation(2019)
3) Meta-Learning Extractor for Music Source separation(2020)
가장 평가 지표가 좋은 meta-learning 논문 부터 공개된 pre-train model을 이용해 Audio Source Separation을 진행해보았고 결과가 만족스러웠다.
3. Audio Reconstruction
맨 처음에 생각했던 것은 frequency domain에서 domain transfer라서 이를 다시 waveform으로 reconstruction 하는 작업이 필요했다. 여기에 쓰이는 알고리즘은 1984년에 발표된 Griffin-Lim을 주로 사용한다. 하지만 resolution 기준에서 좀 더 좋은 결과물을 위해 다음의 논문을 공부했다. Griffin-Lim의 lim은 임재수 MIT 교수님 성함을 딴 것이다. 공부하던 중 한국인 이름이 나와서 반가웠다:)
1) Signal Esitmation from Modified Short-time fourier transform(Griffin-Lim)
2) WaveNet
3) Deep griffin Lim
2)WaveNet은 time domain에 waveform을 generation하는 un-supervised model이다. 여러 분야에 응용되는데, 위에서 살펴본 4)Timbretron 논문에서 audio reconstruction에 griffin-lim 대신 사용했는데 성능이 더 좋았다고 한다. 또한 5) Universial Music translation에서는 WaveNet을 이용해서 Auto-encoder를 만든다.
위에서도 언급했듯이 Audio reconstruction은 frequency domain에서 transfer를 진행할 때 필요한 것이고, time domain에서 하면 waveform 형태가 유지되기 때문에 불필요하다.
Architecture
Architecture는 두가지로 나눠서 진행한다. 1) 하나는 frequency domain에서 cqt를 활용한 cycleGAN. 2) 다른 하나는 time domain에서 WaveNet decoder를 generator로 하는 cycleGAN.


1) frequency domain
CQT를 이미지로 생각, 15s로 악기분리된 음원(1 x 480000, sr = 32000) - 푸리에 변환 -> CQT(84 x 938) CQT 차원이 좀 작은것 같기도 하고.. libroasa parameter로 튜닝 가능한 부분!
악기 별로 cycleGAN, 데이터는 악기별 input A(Jazz) & input B(Pop)
cycleGAN generator는 WaveNet, CQT shape 때문에 6번까지만 다운 샘플링 가능(84 -> 1). 또한 CQT shape이 2의 지수승이 아니므로, 인코딩 layer ouput과 디코딩 layer output이 달라 skip-connection이 안됨. 다음 그림을 보면

(3, 512, 2, 29)에 대응되는 디코딩 layer output이 (3, 512, 2, 28) 이므로 문제가 생김.
따라서 각 디코딩 단에 nn.ReflectionPad2d layer를 추가해 skip-connection이 가능하게 shape을 맞춰 주었다. 구체적으로는 다음과 같이 부족한 방향으로 패딩을 추가했고 위/아래, 왼쪽/오른쪽을 번갈아 주어 데이터에 영향을 최소화 하고자 했다. 한쪽에 몰아넣는게 좋으려나? 별 상관없을 것 같기도.., Reflectionpadding 말고 다른 padding이 나으려나?

input data에 float( ).cuda( )를 해서 네트워크에 넣었다.

최종 generator의 각 layer output은 다음과 같다.
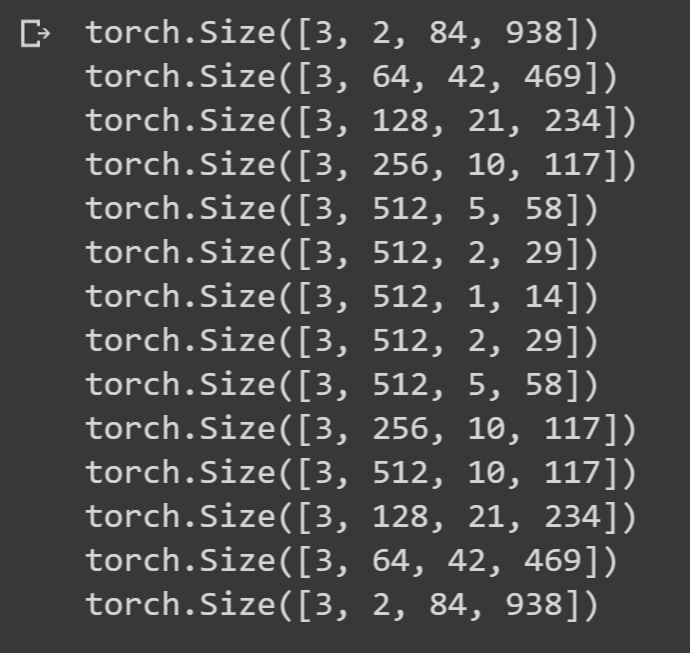
모든 layer에 batchnorm 대신 instancenorm 사용했다. 이외에 kernel size, stride 등 hyper parameter는 pix2pix 논문을 따랐다. kernel size 4인게 문제 되려나?
Discriminator는 다음과 같이 구현했다.

original cycleGAN과 다른점은 마지막에 average pooling을 안하고 sigmoid로 값을 뺐다는 점.
5.20
Time domain(교정) cycleGAN은 G, D 둘다 WaveNet 사용
채널방향으로 all을 concat해주는 것은 cycleGAN 내부에서 문제가 생기므로 보류. 일단은 1. generator 채널은 1로 고정 대신 all을 2. wavenet 컨디션으로 활용 할 여지 있음
Frequency domain에서 generator로 사용할 만한 네트워크 implement(autoencoder or resnet) 찾아보기, spectrogram에 일반적인 cnn(3x3)을 적용하는 것 보다 좋은 방법이 없을까?
trained generator로 라벨을 만들고 다른 train set을 input으로 해서 TasNet loss를 적용해 inference 단에 resolution을 올릴 수도..?
CycleGAN to frequency domain implement
In CycleGAN training, because we made several architectural changes, we retuned the hyperparameters. The weighting for our cycle consistency loss is 10 and the weighting of the identity loss is 5. In the original CycleGAN the weighting of identity loss is constant throughout training but in our experiment, it stays constant for the first 100000 steps, then it starts linearly decay to 0. We set the weighing for Gradient Penalty to be 10, as was suggested in Gulrajani et al. (2017). Our learning rate is exponentially warmed up to 0.0001 over 2500 steps, stays constant, then at step 100000 starts to linearly decay to zero. The total training step is 1.5 million steps, trained with Adam optimizer (Kingma and Ba, 2014) with β1 = 0 and β2 = 0.9, with a batch size of 1.
librosa.cqt에서 default로 normalize 해주므로 data transform에서 Normalize 뺀다.
data agumentation을 time or frequency domain 어디서 해주지?
hop_length=512 exceeds minimum CQT filter length=136.203 'This will probably cause unpleasant acoustic artifacts. ' 'Consider decreasing your hop length or increasing the ' 'frequency resolution of your CQT. 문제 발생, cqt 를 waveform으로 복원했을 때, resolution 문제가 생길거라는 경고, 실제로 resolution이 엉망 -> cqt 파라미터 조정(hop_length를 줄이거나, n_bin, bins_per_octave 를 늘려주자)
librosa.cqt, mel-spectrogram을 써서 음원을 변환한 뒤, 다시 audio로 복원하면 resolution이 엉망..ㅠㅠ 왜 그렇고 어떻게 해결해야되나..
input 음원이 separation되서 resolution이 별로 -> FMA 데이터 셋 대신에 멜론에서 직접 뽑은 노래들로 데이터셋을 구성?! 장르 간 purity를 유지하는데도 도움이 될 듯?
5.27
상형 - rock 200곡 올리기(pop지우고), 전처리 코드 - 앞뒤 10초 버리고 random crop 10초씩 20개, TasNet 코드 확인
교정 - time domain 결과 값까지 다음주에 들어보게, resample(22050, 16000)
현 - frequecy domain - 다른 GAN 모델 찾아보기, reconstruction resoluon 확인
MELGAN-VC
CycleGAN에서 사용하는 pixel-wise loss 대신 인풋(x)과 G(x) 사이의 관계를 유지시키는 방법을 찾자

spectrogram을 vector로 인코딩해서 content information을 original latent space에서 포착, 전체 이미지가 아닌 이 vector로 관계를 유지시키자. (Transforming vector Learning _ TraVeL) 즉 x, G(x)를 비교하는 것이 아닌 이 값들의 latent vector인 S(x), S(G(x))를 비교하자. 왜냐면 직접 데이터를 비교하면 pixel wise loss만을 고려하기 때문!
이는 siamese network로 달성한다.
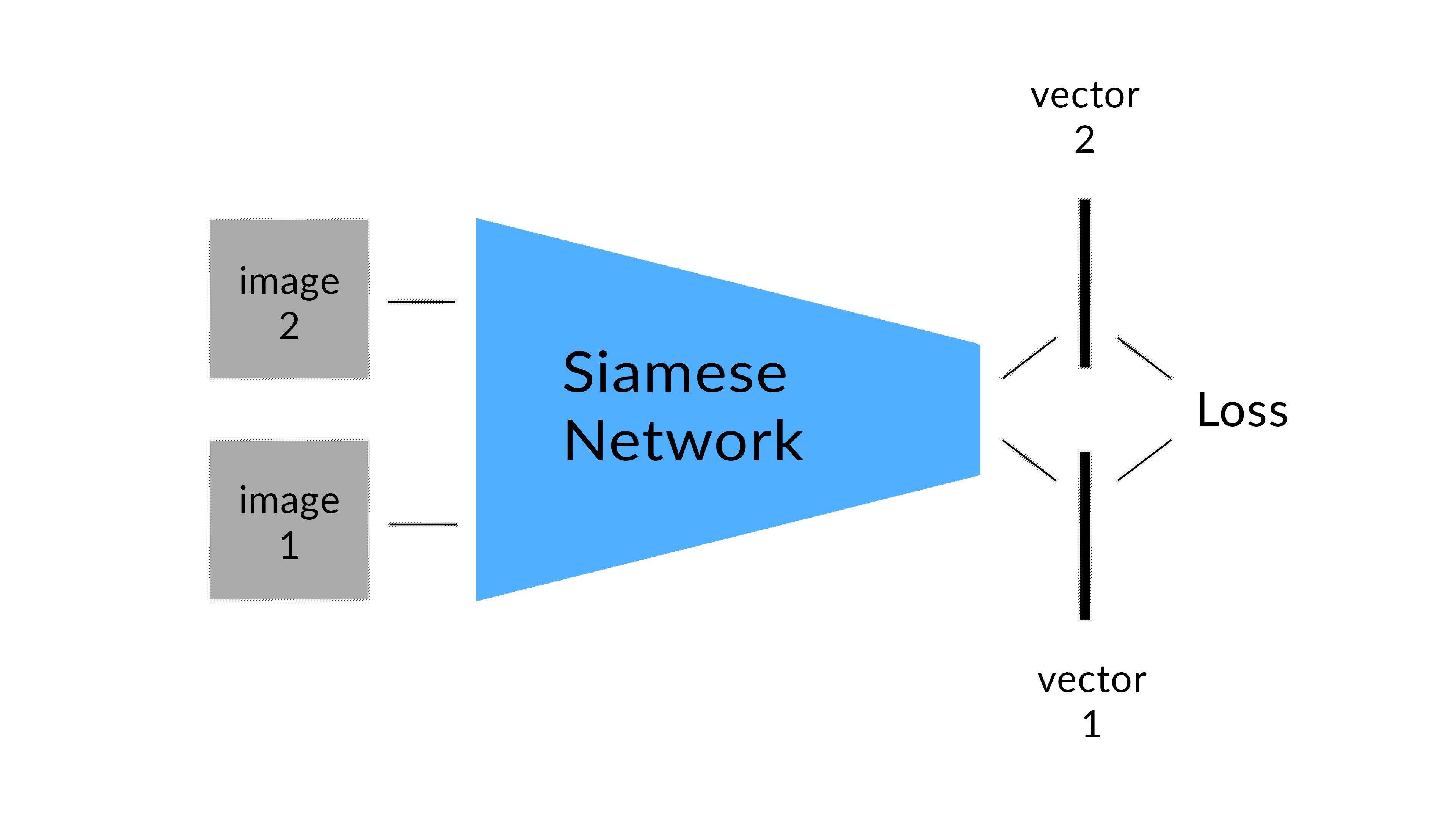
다음과 같이 S로 인코딩 된 벡터와 G로 생성된 데이터를 S로 인코딩했을 때, 둘을 동일하게 유지한다.
S(A1) - S(A2) = S(G(A1)) - S(G(A2))
일반적인 GAN이 geomrtric 정보만을 보존하는 반면 위 방법을 통해 semantic information을 보존할 수 있다.
TraVeL loss를 사용해서 최적화한다. 이 loss는 유클리디안 거리와 cosine 유사도를 둘다 고려한다.

G, S가 동시에 학습되야 하므로, gradient가 두 네트워크에 모두 backpropa 되고 weight를 업데이트한다.

네트워크에 공통적으로, Spectral Normalization이 쓰임. -> Generative model 학습의 불안정성을 잡기위함. -> Time domain에 CycleGAN에도 적용해볼수도?


0610
MelGAN-VC 기존 논문에서 시도했던 방식에서 Generator -> 일반적인 UNet 구조로 바꿈
Discriminator와 Siamese는 그대로 유지(kernel_size가 특이함, frequency를 한번에 보는 방식), generator와 구조적으로 달라졌는데 괜찮을까?
batch_size : 16으로 testing
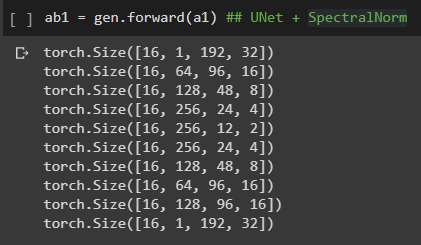

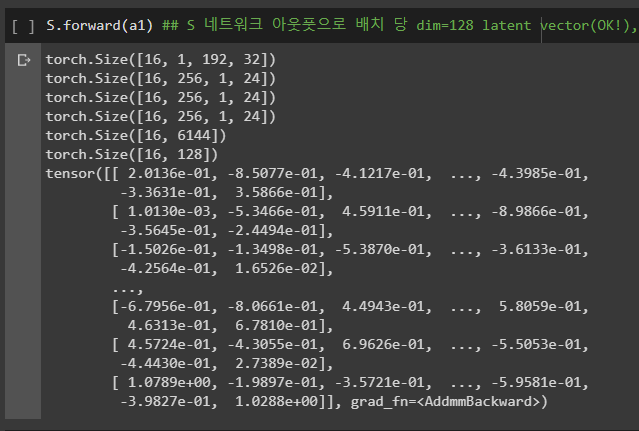
SpectralNorm도 따로 class를 선언하여 pytorch nn 단에서 적용
DataSet 재구성 : rock, jazz
1. gtzan 각 100곡씩
2. 멜론에서 휴리스틱하게 락과 재즈에 해당하는 곡들을 선별, 장르의 특성을 반영하면서 내부적인 purity를 유지하게 샘플링함. rock 100곡, 총 duration 415분 8초/ 주로 일렉기타가 들어간 밴드 사운드 노래로 채움. -> separation 하고 나니까, other 가 385분.. 30분 정도 날라갔다. why?
gtzan rock -> (294, 220480) -> (294, 192, 1149, 1) -> (3528, 192, 96, 1)
Melon rock -> (2301, 220480) -> (2301, 192, 1149, 1) -> (27612, 192, 96, 1)
gtzan jazz -> (300, 220480) -> (300, 192, 1149, 1) -> (3600, 192, 96, 1)
Time domain(교정)
WaveNet 아웃풋은 softmax -> argmax로 8bit(256) 값 중 하나로 assign 된다. 원래 WaveNet은 이를 CE를 통해 타겟 음원과 loss를 계산해 학습한다. 하지만, 우리 task는 WaveNet 뒤에 discriminator가 연결되어 있으므로 GAN 학습 시 gradient가 G(WaveNet)까지 흘러가야한다. 하지만, argmax 함수가 미분 불가라 일반적인 backpropagation이 불가능하다. 이에 대한 해결책으로
1. 미분 가능한 근사 argmax 함수 사용
2. softmax, argmax layer를 버리고 tanh를 통해 WaveNet 아웃풋을 raw waveform으로 맞춰준 뒤, 이를 8bit mu-law companding, quantization, expand 시켜 D에 넣어준다. (real도 똑같이 처리 후 D에 함께 넣어준다)
Frequency domain(현)
1. SpectralNorm이 적용이 되었나? -> yes
2. zero padding 괜찮은가? 저렇게 same size로 유지하려는 이유는? -> 해보고, kernel_size랑 padding(zero, reflect) 같이 고려해봐야 될 듯
3. G를 UNet + spectral로 바꿨는데 D는 그대로 MelGAN 구조를 써도 되나 -> 구조보다는 G, D의 복잡도가 중요. 왜냐면 한 쪽이 너무 강하게 학습되면 안되기 때문. # of parameters, layers/ 상대적으로 D보다는 G를 강력하게 만드는게 좋음. D가 학습되기 쉽기 때문(이진 분류).
4. D 최종 activation 뭐써야되지? 일단 tanh 했음, CycleGAN은 sigmoid 인듯? -> 상관없다
6. SpectralNorm - time domain에 cycleGAN에도 적용해봐도? -> yes
7. 96으로 split하는거 괜찮나.. 1초도 안되는것 같은데 거기서 어떤걸 잡을 수 가 있나 -> 해보고 split 범위를 넓혀보자
8. gtzan이랑 melon 섞어서 셔플? -> yes
9. generator 아웃풋 == D 인풋(구조랑 차원)
7.10
frequency domain 결과값 wave로 근사시킬때 waveGLOW 써보자
*여러 문제와 해결 방안
1. wavenet 무거워서 colab에서 안 돌아감
2. frequency domain 결과가 처참
3. separation 음원 resolution이 안 좋음
4. 결론적으로 time domain에 집중하기로
-------------------------------------------------------
5. wave를 2D로 변환해서 나이브 GAN 적용 해보자
6. Universial 이용해서 jazz piano 보코더 만들어서 tranlation(최후의 보루)
7. datasets 및 task 새로 구축
1) 기존 스타일 변환 -> 밴드음악 to jazz 피아노
2) 이를 위한 datasets, 밴드음악은 musdb stems 데이터 활용, jazz piano는 유튜브
3) jazz piano 종류가, cover, only jazz piano, jazz 쿼텟 정도
'Project' 카테고리의 다른 글
| [Project] 음악 스타일 변환 with GAN, Autoencoder🎵 (0) | 2020.11.01 |
|---|
